2.Run Paul Murrell’s RGraphics basic R programs (murrell01.R in GitHub).
a. Be sure to run line by line and note the changes.
b. Pay attention to the comments and address the question if there is one.
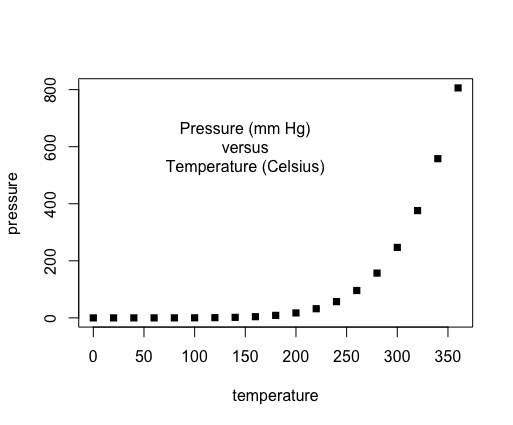
i. plot(pressure, pch=16) # Can you change pch?
Yes, you can change the pch. Changing the pch alters the points on the plotline of the graph. For example, the value 16 for the pch are circles. If the pch is changed to 15, the circles change to squares.
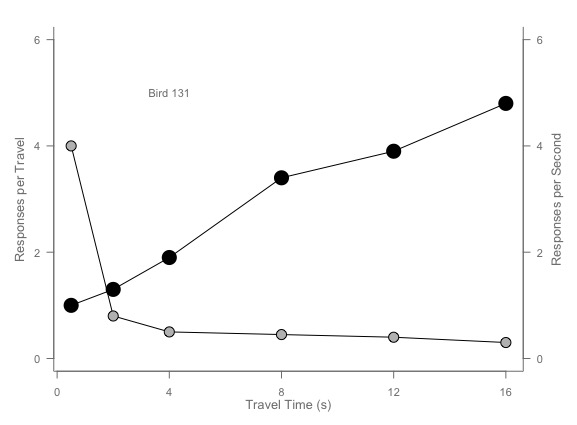
ii. points(x, y1, pch=16, cex=3) # Try different cex value?
The cex value changes the size of the points on the plot line. The larger the cex value, the larger the points on the plot line.
iii. axis(1, at=seq(0, 16, 4)) # What is the first number standing for?
This command generates the x axis on the chart. The x axis is labelled “Travel Time in seconds”. This means that the first number on the x axis, 0, signifies when the time measurement begins; it is just before the responses are being recorded.
iv. Generations of these Murrell charts are below.
Figure 1: Pressure plot with the pch value changed from 16 to 15.
Figure 2: Bird 131 Travel scatterplot with the cex value changed from 2 to 3, as well as the “background color” of the white circles changed to grey circles.
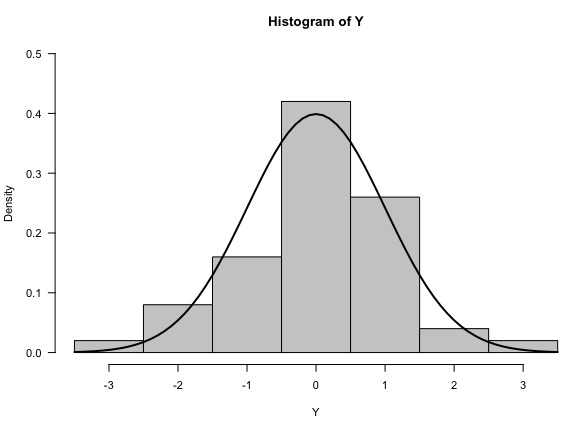
Figure 3: Histogram of Y.
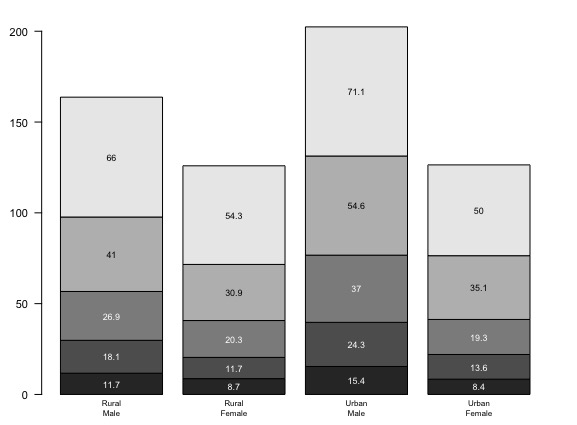
Figure 4: Barplot.
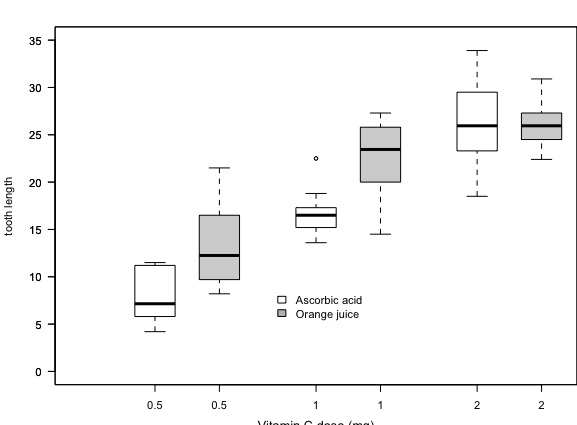
Figure 5: Boxplot of Vitamin C dose (mg) on tooth growth/length.
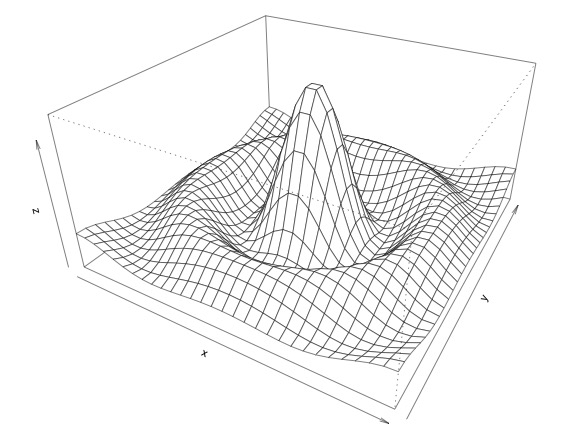
Figure 6: Perspective plot.
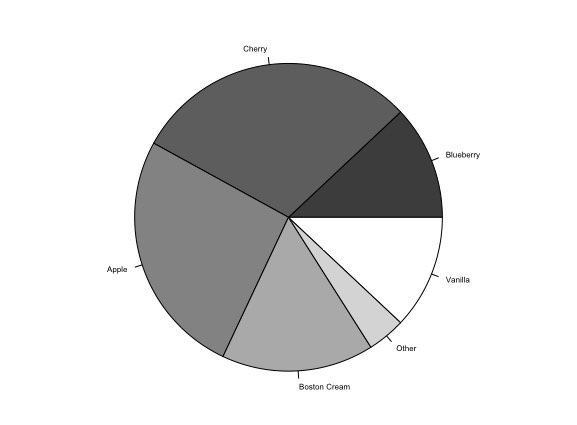
Figure 7: Pie chart of pie sales.
v. Try these functions using another dataset. Be sure to work on the layout and margins.
See Part C below. These functions will be used on the Happy Planet Index (HPI) data set.
c. Plotting functions using the Happy Planet Index (HPI) data set.
# Setting up the new R environment, starting fresh, click run!rm(list=ls())# Setting up the working directory, click run!setwd("~/Documents/Fall 2022/EPPS 6356/samantha-manuel.github.io")# Turning on the packages required for HW2, click run!library(Hmisc)
Loading required package: lattice
Loading required package: survival
Loading required package: Formula
Loading required package: ggplot2
Attaching package: 'Hmisc'
The following objects are masked from 'package:base':
format.pval, units
Attaching package: 'maps'
The following object is masked from 'package:purrr':
map
library(countrycode)library(ggplot2)# Reading the file, click run!HPI <-read.xlsx("~/Documents/Fall 2022/EPPS 6356/samantha-manuel.github.io/happy-planet-index-2006-2020-public-data-set.xlsx", sheetIndex =2)#Remove first 7 rows and save as 'HPI2019', click run! HPI2019 <- HPI[-c(1:7),]view(HPI2019)#remove 3rd column ('NA..2') as it is not needed for further analysis, click run! HPI2019 <- HPI2019 %>%select(-'NA..2')#Rename columns for simplicity, click run!HPI2019 <- HPI2019 %>%rename(HPI_rank ='NA.') %>%rename(Country ='X1..Rankings.for.all.countries..2006...2020') %>%rename(ISO ='NA..1') %>%rename(Continent ='NA..3') %>%rename(Pop ='NA..4') %>%rename(Life_Exp ='NA..5') %>%rename(Wellbeing ='NA..6') %>%rename(Ecological_Footprint ='NA..7') %>%rename(HPI ='NA..8') %>%rename(Biocapacity ='NA..9') %>%rename(GDP_per_capita ='NA..10')#Remove row with index number 8 so the data set starts with 'Costa Rica', click run! HPI2019 <- HPI2019[-1,]#Change to show a maximum of 15 digits, click run! options(digits =15)#Convert data type from character to numeric for selected columns, click run! HPI2019 <- HPI2019 %>%mutate(HPI_rank =as.numeric(HPI_rank)) %>%mutate(Pop =as.numeric(Pop)) %>%mutate(Life_Exp =as.numeric(Life_Exp)) %>%mutate(Wellbeing =as.numeric(Wellbeing)) %>%mutate(Ecological_Footprint =as.numeric(Ecological_Footprint)) %>%mutate(HPI =as.numeric(HPI)) %>%mutate(Biocapacity =as.numeric(Biocapacity)) %>%mutate(GDP_per_capita =as.numeric(GDP_per_capita))
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
view(HPI2019)#View map of data 'data_map', click run!require(maps)require(countrycode)data_map <-map_data("world")view(data_map)#Consulting the countrycode documentation for details, click run! ?countrycode#Create a new column in data_map called 'ISO' to match the ISO column in the HPI2019 table, click run! data_map$ISO =countrycode(data_map$region, origin="country.name", destination ='iso3c')
Warning in countrycode_convert(sourcevar = sourcevar, origin = origin, destination = dest, : Some values were not matched unambiguously: Ascension Island, Azores, Barbuda, Bonaire, Canary Islands, Chagos Archipelago, Grenadines, Heard Island, Kosovo, Madeira Islands, Micronesia, Saba, Saint Martin, Siachen Glacier, Sint Eustatius, Virgin Islands
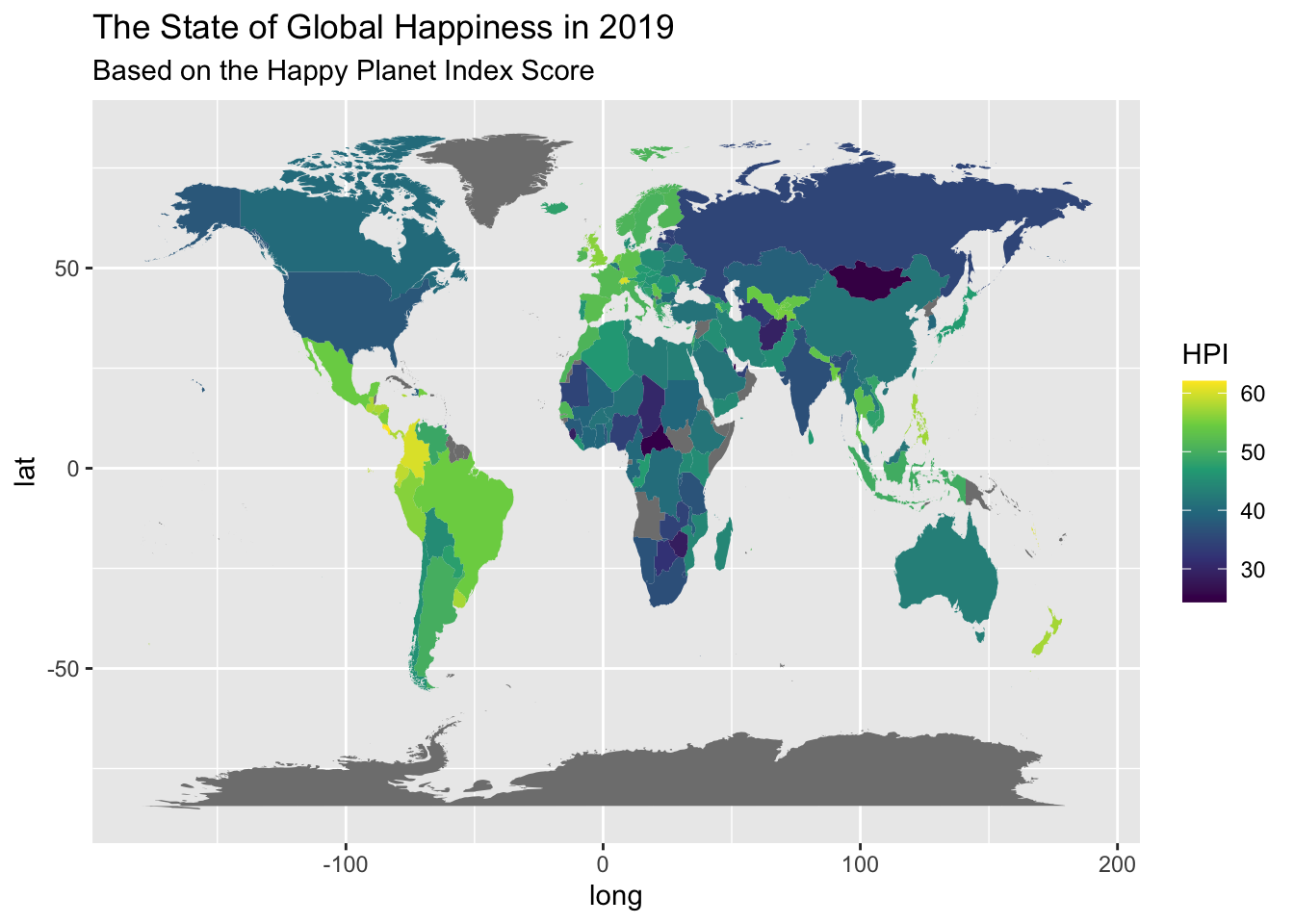
#View updated data_map, click run! view(data_map)#Merge HPI2019 with data_map to create a data set which will be used to plot HPI in the world map, click run! mergedHPI2019 <-full_join(data_map, HPI2019, by="ISO")#View merged data set, click run! view(mergedHPI2019)#Generate the world map chart, click run! ggplot(mergedHPI2019, aes(x = long, y = lat, group = group, fill = HPI)) +geom_polygon() +scale_fill_viridis_c() +labs(title ="The State of Global Happiness in 2019", subtitle ="Based on the Happy Planet Index Score")
#Generate a barplot of the effect of GDP on HPI, click run! barplot(table(mergedHPI2019$HPI,mergedHPI2019$GDP_per_capita), beside=TRUE, main="The Effect of GDP on HPI", xlab="GDP", ylab="HPI")