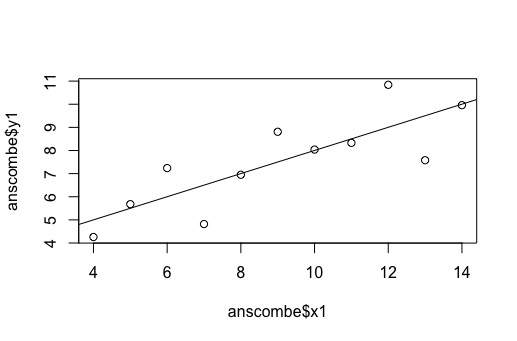
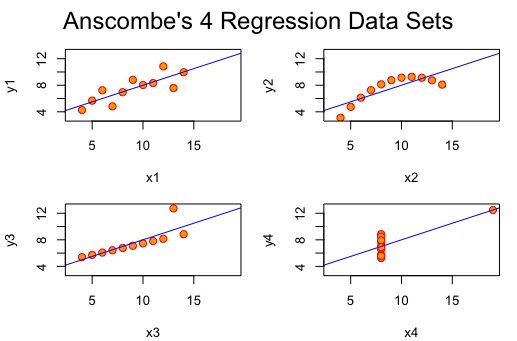
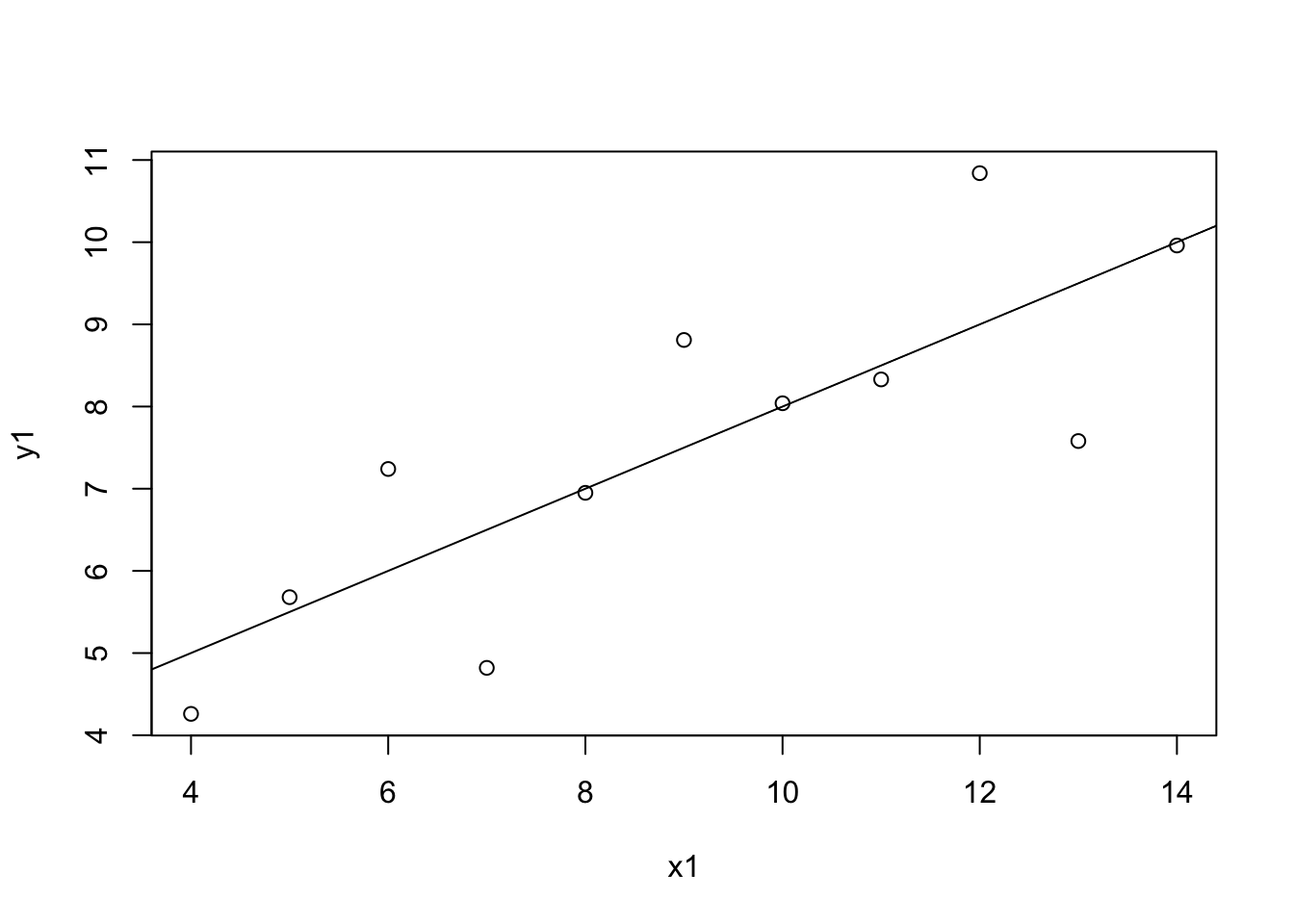
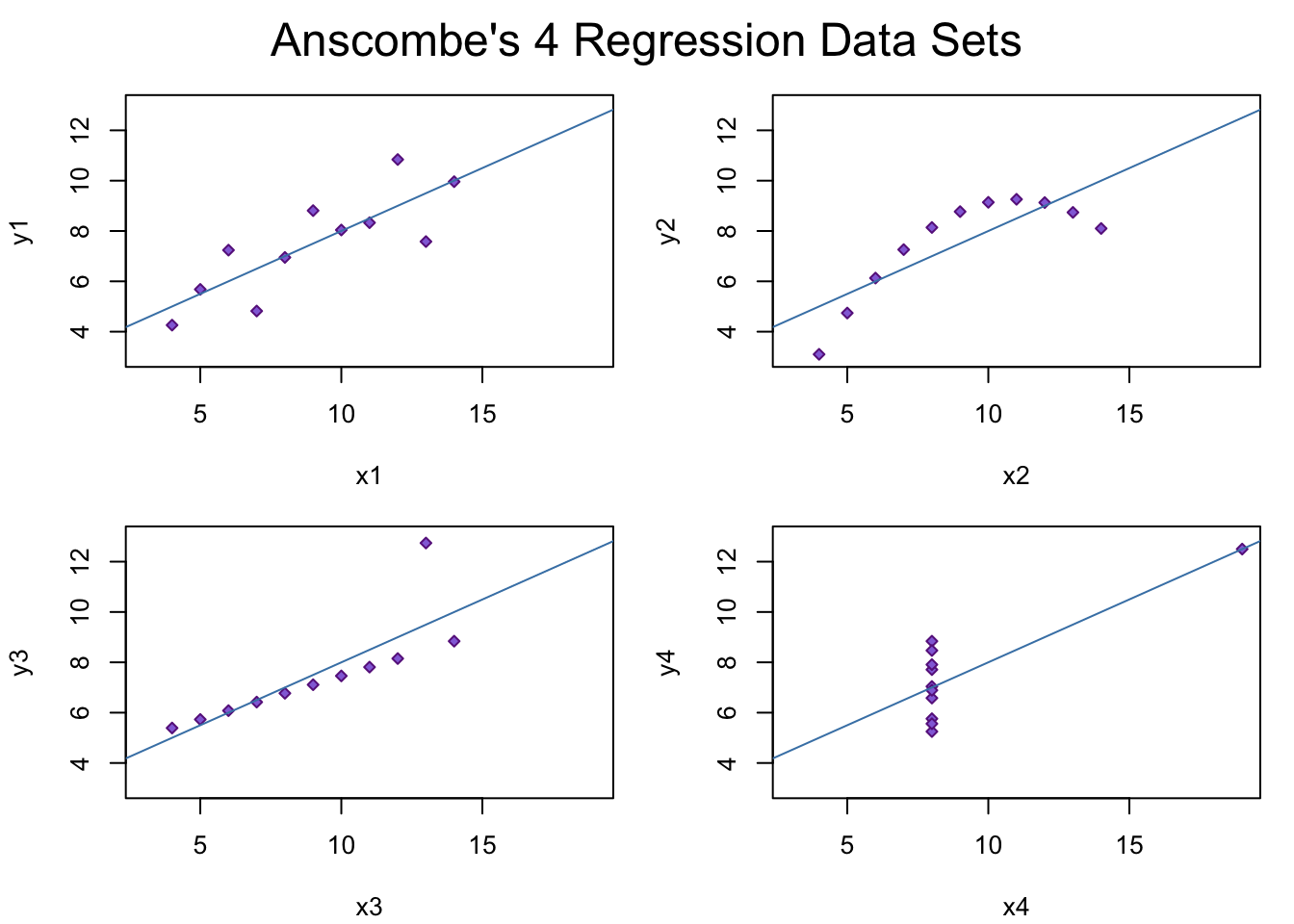
As seen in Figure 1, a regression plot is appropriate for data visualization and analysis. The plot points generally fit the regression line. However, because the plot points are very spaced out, the R^2 value may be very small, as the regression line does not fit plot points very well.
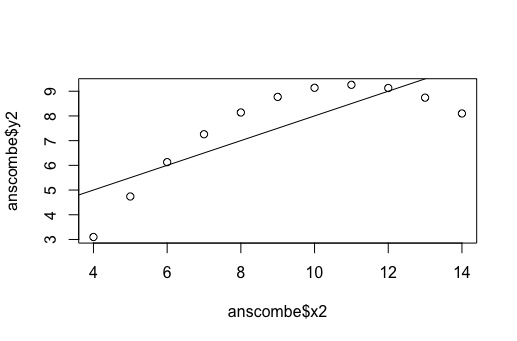
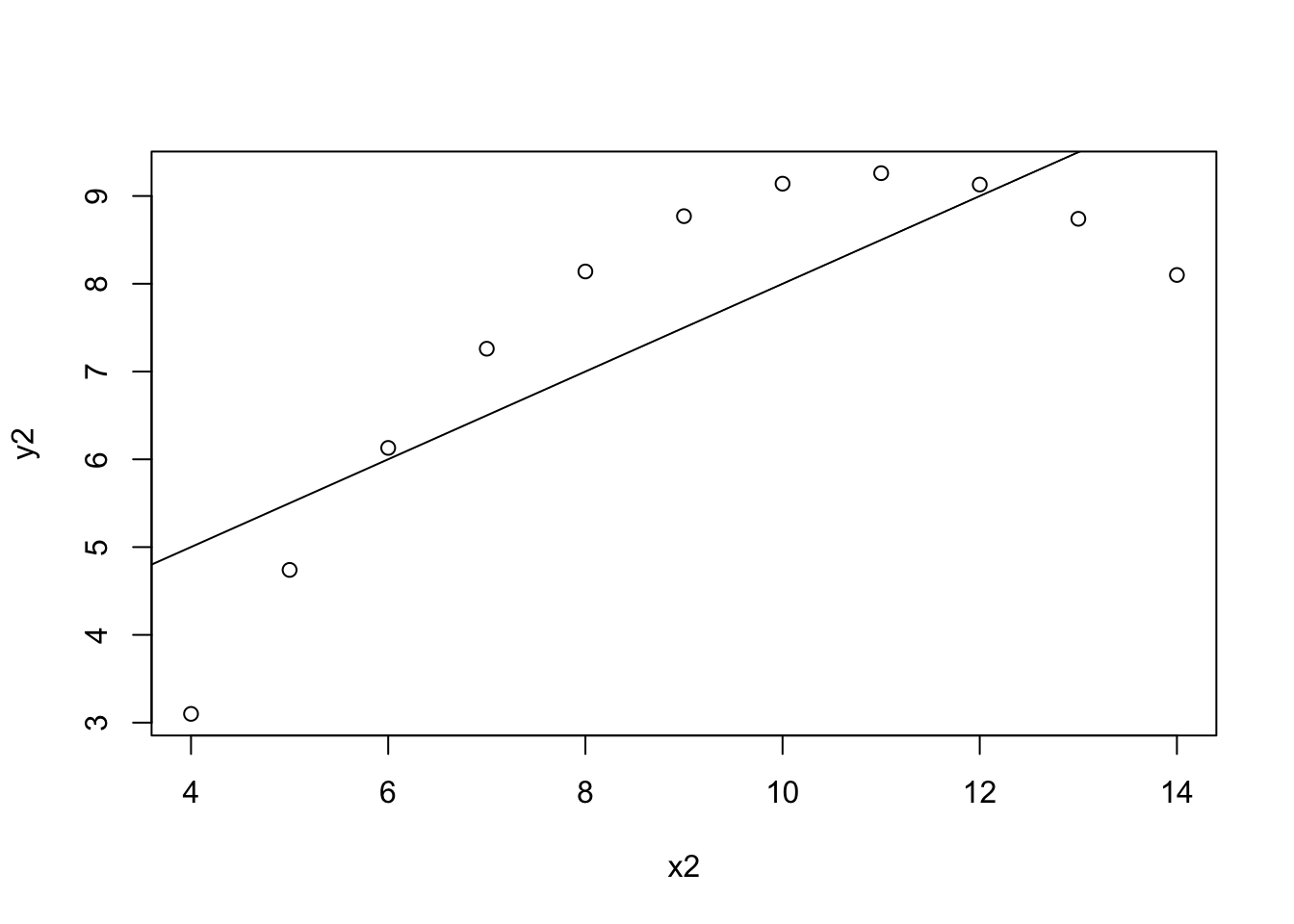
Figure 2: Regression plot of X2 and Y2.
As seen in Figure 2, a regression plot is most likely not the best tool for data analysis. This is because all of the plot points resemble a parabolic function. For this reason, a different or supplementary data visualization/analysis tools may be required.
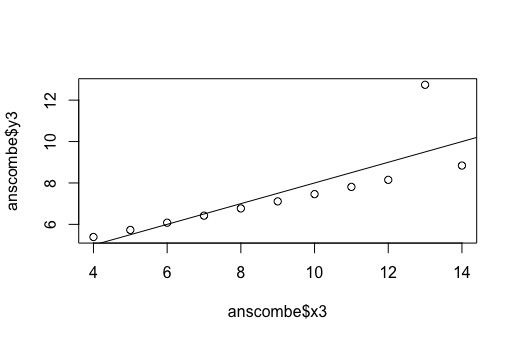
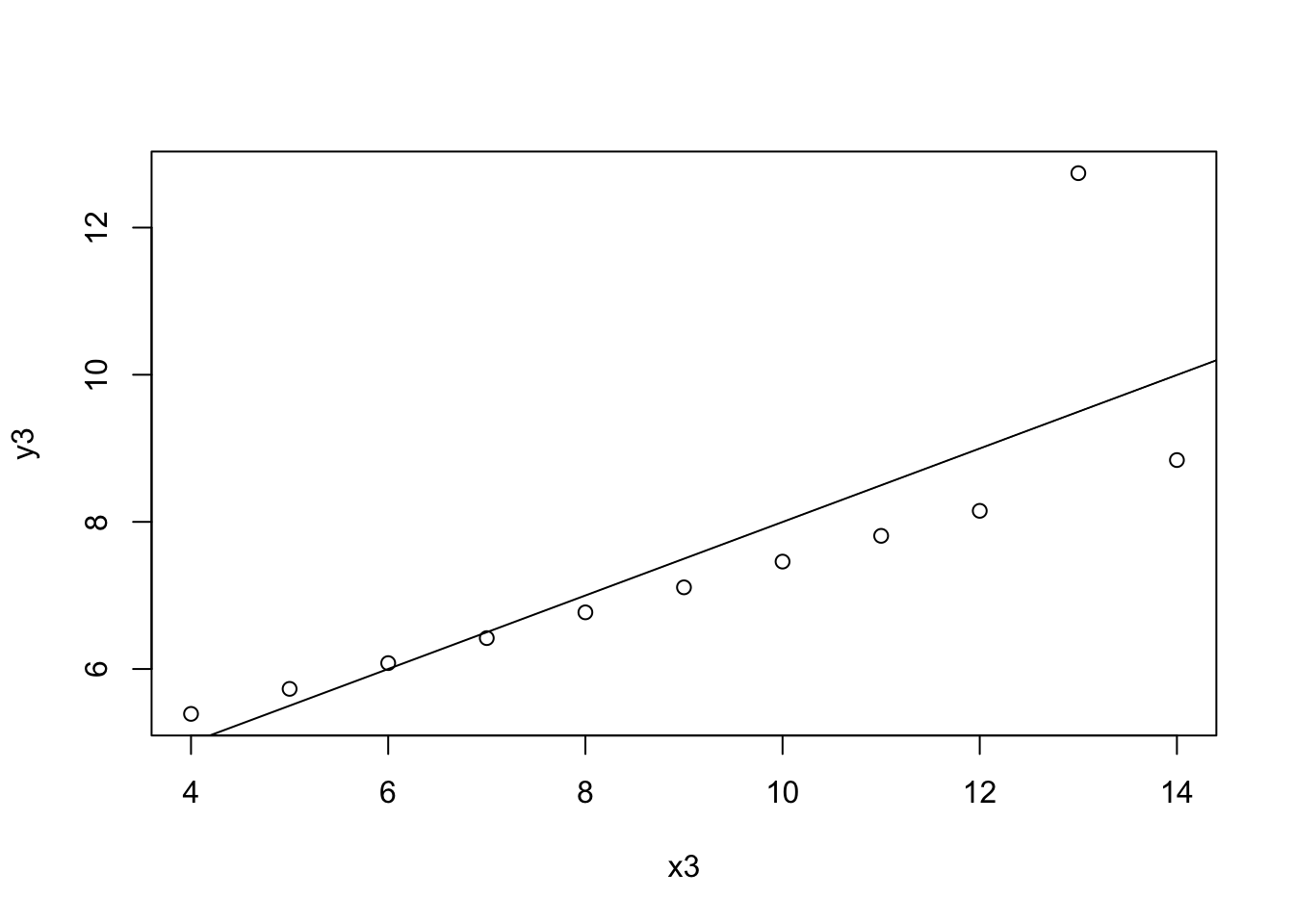
Figure 3: Regression plot of X3 and Y3.
Figure 3 is similar to Figure 1, in that a regression plot is appropriate for data visualization and analysis. The plot points generally fit the regression line, except for one outlier point at x=13. It may be beneficial to take this outlier out, and therefore visualize how much better the regression line would fit the data.
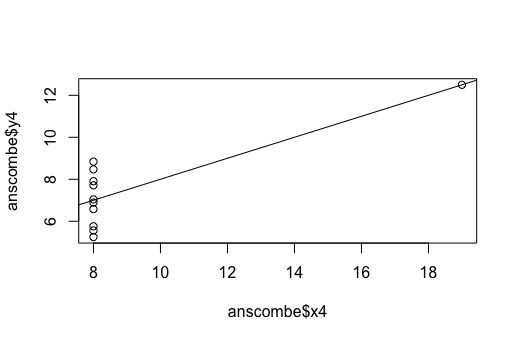
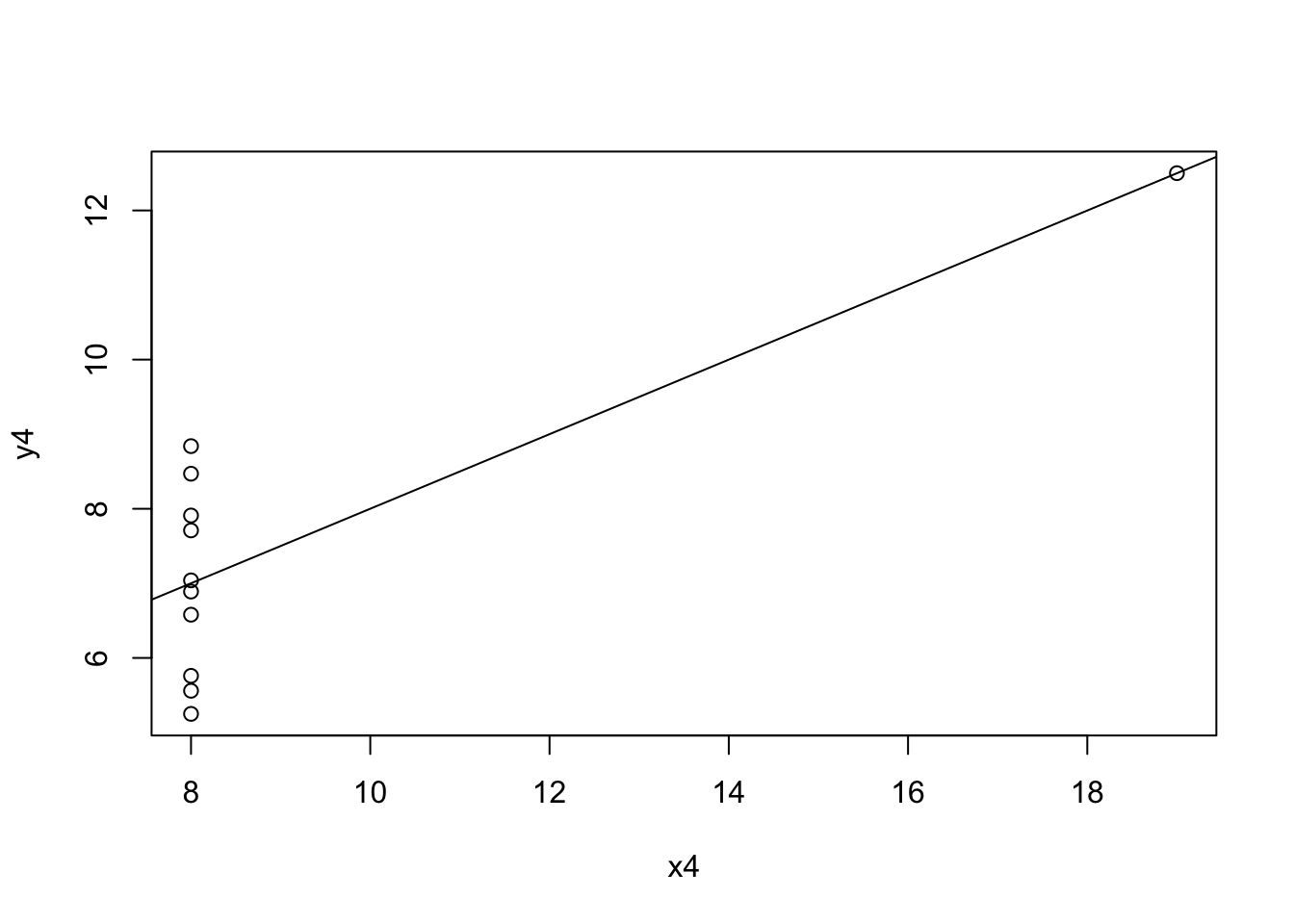
Figure 4: Regression plot of X4 and Y4.
Like Figure 2, a regression plot is most likely not the best tool for data analysis for Figure 4. This is because all of the plot points except for one are all at x=8. For this reason, different or supplementary data visualization/analysis tools are required.
b. Compare different ways to create the plots (e.g. changing colors, line types, plot characters).
Figure 5: Aggregate regression plots from X1-X4 and Y1-Y4.
As seen in Figure 5, all four regression plots were generated as a composite chart by using the code to "plot for a loop". This composite/aggregate chart also was about to generate a title to describe the plots. This code was also able to add further design components such as regression line color, as well as plot point size, color, and shape.
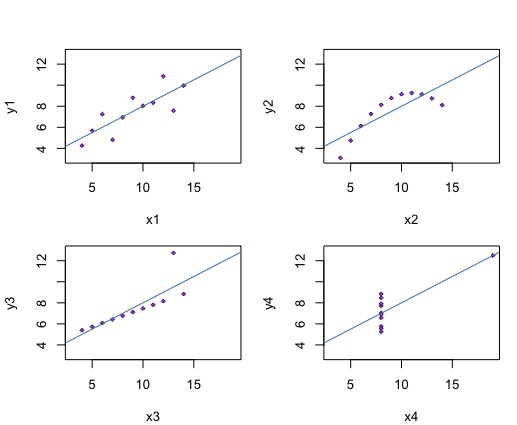
2.Can you finetune the charts without using other packages (consult RGraphics by Murrell).
Figure 6: Finetuned aggregate regression plots for X1-X4 and Y1-Y4.
Above is Figure 6, which is the "finetuned" version of the regression plots for X1-X4 and Y1-Y4, using the RGraphics by Murrell. I changed the plot points to be smaller, so that the reader can more effectively read the charts and distinguish between the plot points. This is especially helpful for Plot 4, where many of the plot points are stacked on top of each other. Making the plot point sizes smaller also allows the reader to be able see the distancebetween plot points easier, as well. I also changed the color of the plot points and regression line to colors that are easier on the eye and less distracting.
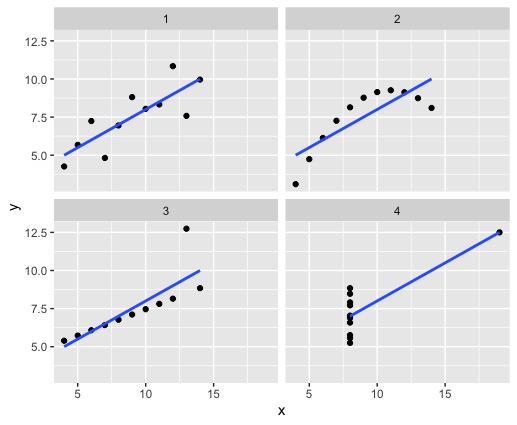
3.How about with ggplot2? (use tidyverse package)
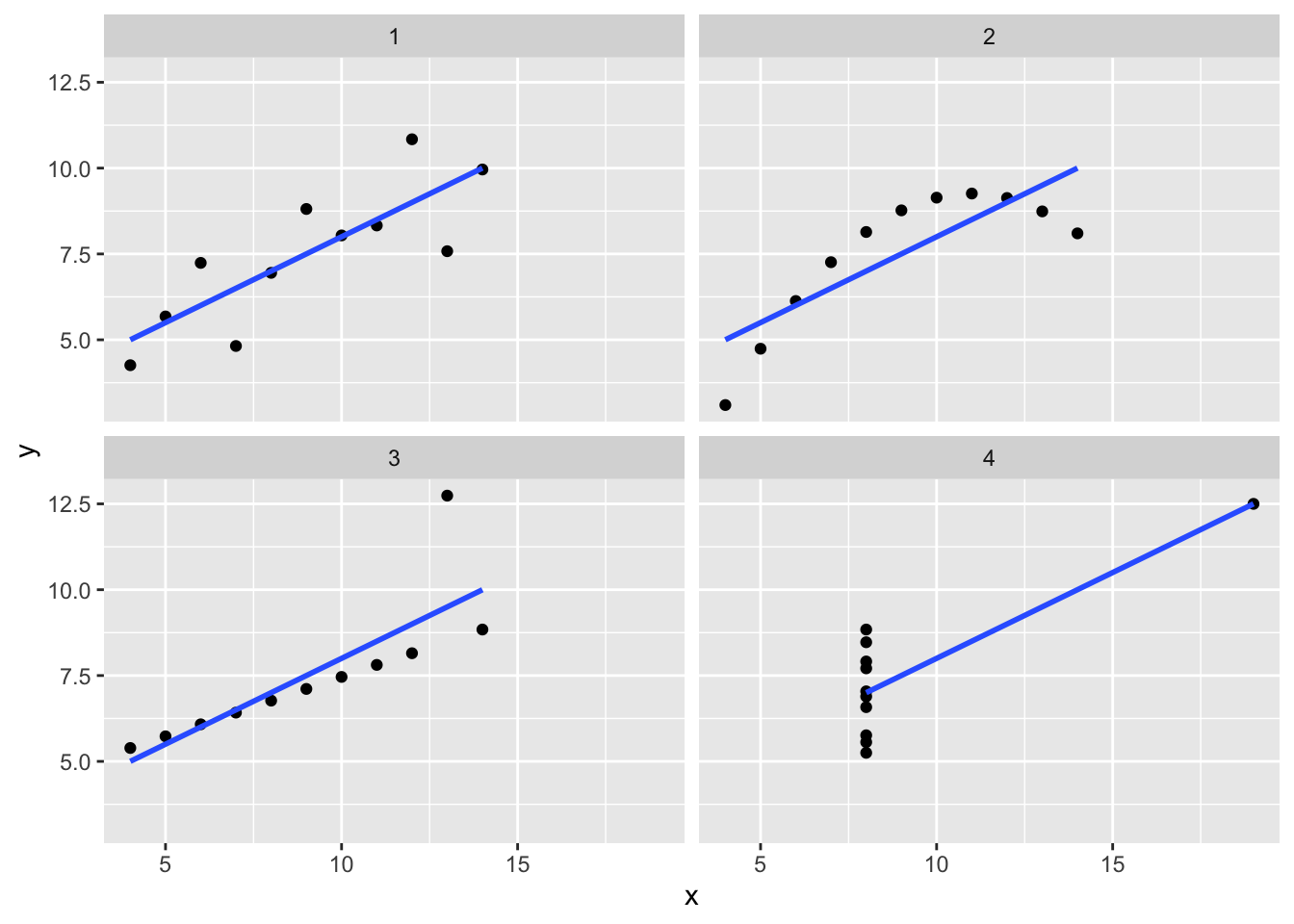
See the code below to see how the ggplot2 function (attached to the tidyverse package) can be used to efficiently generate the four regression plots for Anscombe's (1973) Quartlet. The generated chart is also seen below in Figure 7. This aggregate/composite plot was produced by using only two lines of code, instead of 13+ lines of code the traditional way without the ggplot2 function within the tidyverse package.
Figure 7: Aggregate regression plots from X1-X4 and Y1-Y4 generated using the ggplot2 function.
x1 x2 x3 x4 y1
Min. : 4.0 Min. : 4.0 Min. : 4.0 Min. : 8 Min. : 4.260
1st Qu.: 6.5 1st Qu.: 6.5 1st Qu.: 6.5 1st Qu.: 8 1st Qu.: 6.315
Median : 9.0 Median : 9.0 Median : 9.0 Median : 8 Median : 7.580
Mean : 9.0 Mean : 9.0 Mean : 9.0 Mean : 9 Mean : 7.501
3rd Qu.:11.5 3rd Qu.:11.5 3rd Qu.:11.5 3rd Qu.: 8 3rd Qu.: 8.570
Max. :14.0 Max. :14.0 Max. :14.0 Max. :19 Max. :10.840
y2 y3 y4
Min. :3.100 Min. : 5.39 Min. : 5.250
1st Qu.:6.695 1st Qu.: 6.25 1st Qu.: 6.170
Median :8.140 Median : 7.11 Median : 7.040
Mean :7.501 Mean : 7.50 Mean : 7.501
3rd Qu.:8.950 3rd Qu.: 7.98 3rd Qu.: 8.190
Max. :9.260 Max. :12.74 Max. :12.500
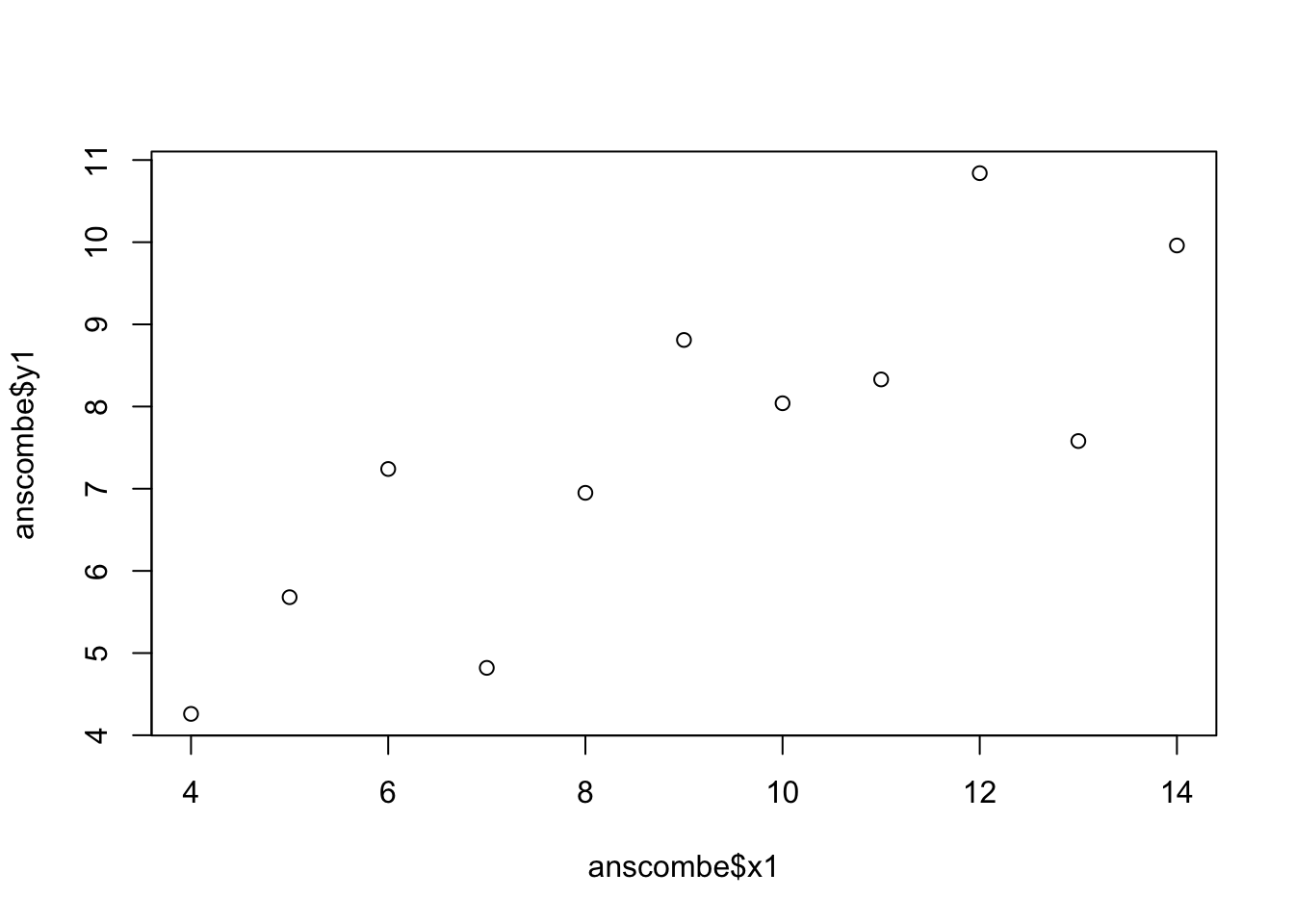
## Simple versionplot(anscombe$x1,anscombe$y1)
summary(anscombe)
x1 x2 x3 x4 y1
Min. : 4.0 Min. : 4.0 Min. : 4.0 Min. : 8 Min. : 4.260
1st Qu.: 6.5 1st Qu.: 6.5 1st Qu.: 6.5 1st Qu.: 8 1st Qu.: 6.315
Median : 9.0 Median : 9.0 Median : 9.0 Median : 8 Median : 7.580
Mean : 9.0 Mean : 9.0 Mean : 9.0 Mean : 9 Mean : 7.501
3rd Qu.:11.5 3rd Qu.:11.5 3rd Qu.:11.5 3rd Qu.: 8 3rd Qu.: 8.570
Max. :14.0 Max. :14.0 Max. :14.0 Max. :19 Max. :10.840
y2 y3 y4
Min. :3.100 Min. : 5.39 Min. : 5.250
1st Qu.:6.695 1st Qu.: 6.25 1st Qu.: 6.170
Median :8.140 Median : 7.11 Median : 7.040
Mean :7.501 Mean : 7.50 Mean : 7.501
3rd Qu.:8.950 3rd Qu.: 7.98 3rd Qu.: 8.190
Max. :9.260 Max. :12.74 Max. :12.500
# Create four model objectslm1 <-lm(y1 ~ x1, data=anscombe)summary(lm1)
Call:
lm(formula = y1 ~ x1, data = anscombe)
Residuals:
Min 1Q Median 3Q Max
-1.92127 -0.45577 -0.04136 0.70941 1.83882
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.0001 1.1247 2.667 0.02573 *
x1 0.5001 0.1179 4.241 0.00217 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.237 on 9 degrees of freedom
Multiple R-squared: 0.6665, Adjusted R-squared: 0.6295
F-statistic: 17.99 on 1 and 9 DF, p-value: 0.00217
lm2 <-lm(y2 ~ x2, data=anscombe)summary(lm2)
Call:
lm(formula = y2 ~ x2, data = anscombe)
Residuals:
Min 1Q Median 3Q Max
-1.9009 -0.7609 0.1291 0.9491 1.2691
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.001 1.125 2.667 0.02576 *
x2 0.500 0.118 4.239 0.00218 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.237 on 9 degrees of freedom
Multiple R-squared: 0.6662, Adjusted R-squared: 0.6292
F-statistic: 17.97 on 1 and 9 DF, p-value: 0.002179
lm3 <-lm(y3 ~ x3, data=anscombe)summary(lm3)
Call:
lm(formula = y3 ~ x3, data = anscombe)
Residuals:
Min 1Q Median 3Q Max
-1.1586 -0.6146 -0.2303 0.1540 3.2411
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.0025 1.1245 2.670 0.02562 *
x3 0.4997 0.1179 4.239 0.00218 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.236 on 9 degrees of freedom
Multiple R-squared: 0.6663, Adjusted R-squared: 0.6292
F-statistic: 17.97 on 1 and 9 DF, p-value: 0.002176
lm4 <-lm(y4 ~ x4, data=anscombe)summary(lm4)
Call:
lm(formula = y4 ~ x4, data = anscombe)
Residuals:
Min 1Q Median 3Q Max
-1.751 -0.831 0.000 0.809 1.839
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.0017 1.1239 2.671 0.02559 *
x4 0.4999 0.1178 4.243 0.00216 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.236 on 9 degrees of freedom
Multiple R-squared: 0.6667, Adjusted R-squared: 0.6297
F-statistic: 18 on 1 and 9 DF, p-value: 0.002165
plot.new
function ()
{
for (fun in getHook("before.plot.new")) {
if (is.character(fun))
fun <- get(fun)
try(fun())
}
.External2(C_plot_new)
grDevices:::recordPalette()
for (fun in getHook("plot.new")) {
if (is.character(fun))
fun <- get(fun)
try(fun())
}
invisible()
}
<bytecode: 0x7fcc40a494e0>
<environment: namespace:graphics>