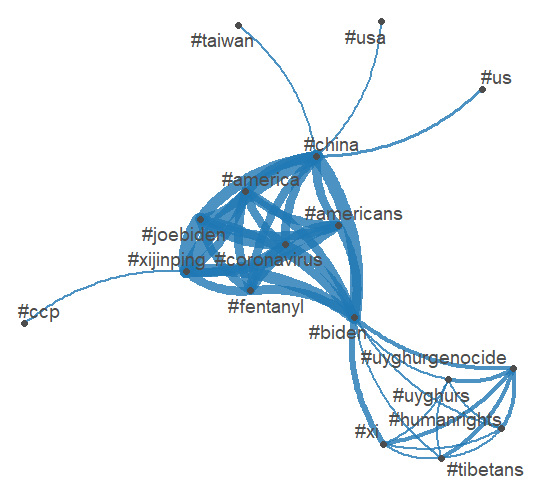
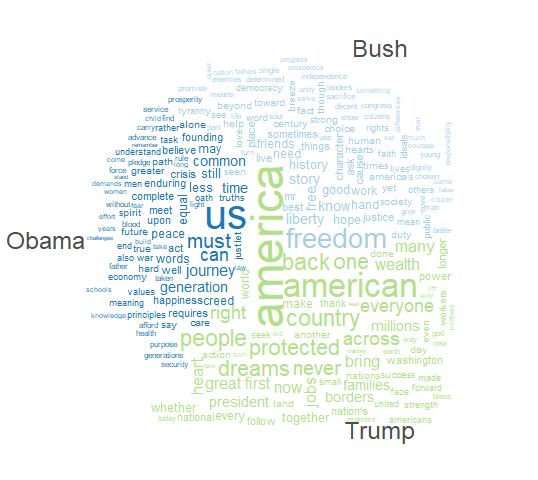
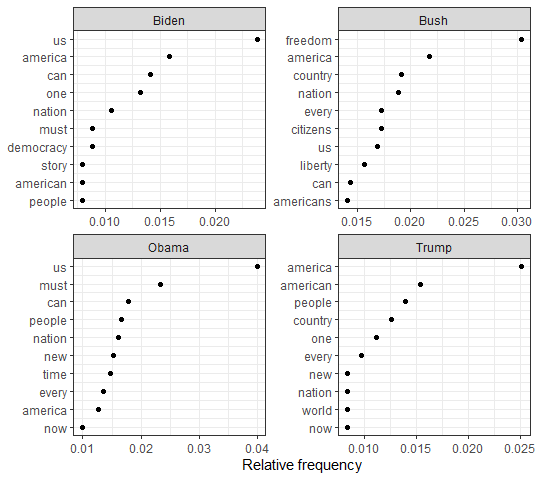
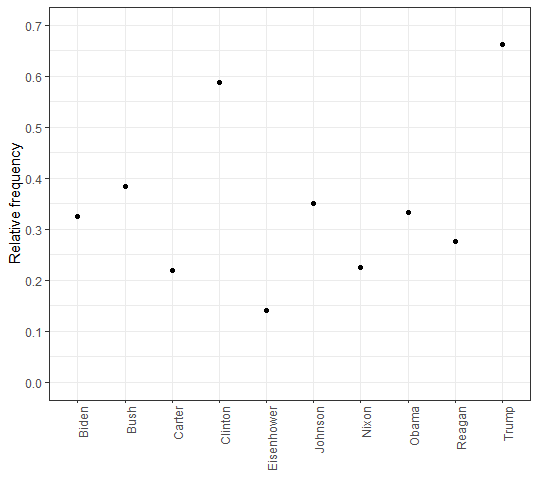
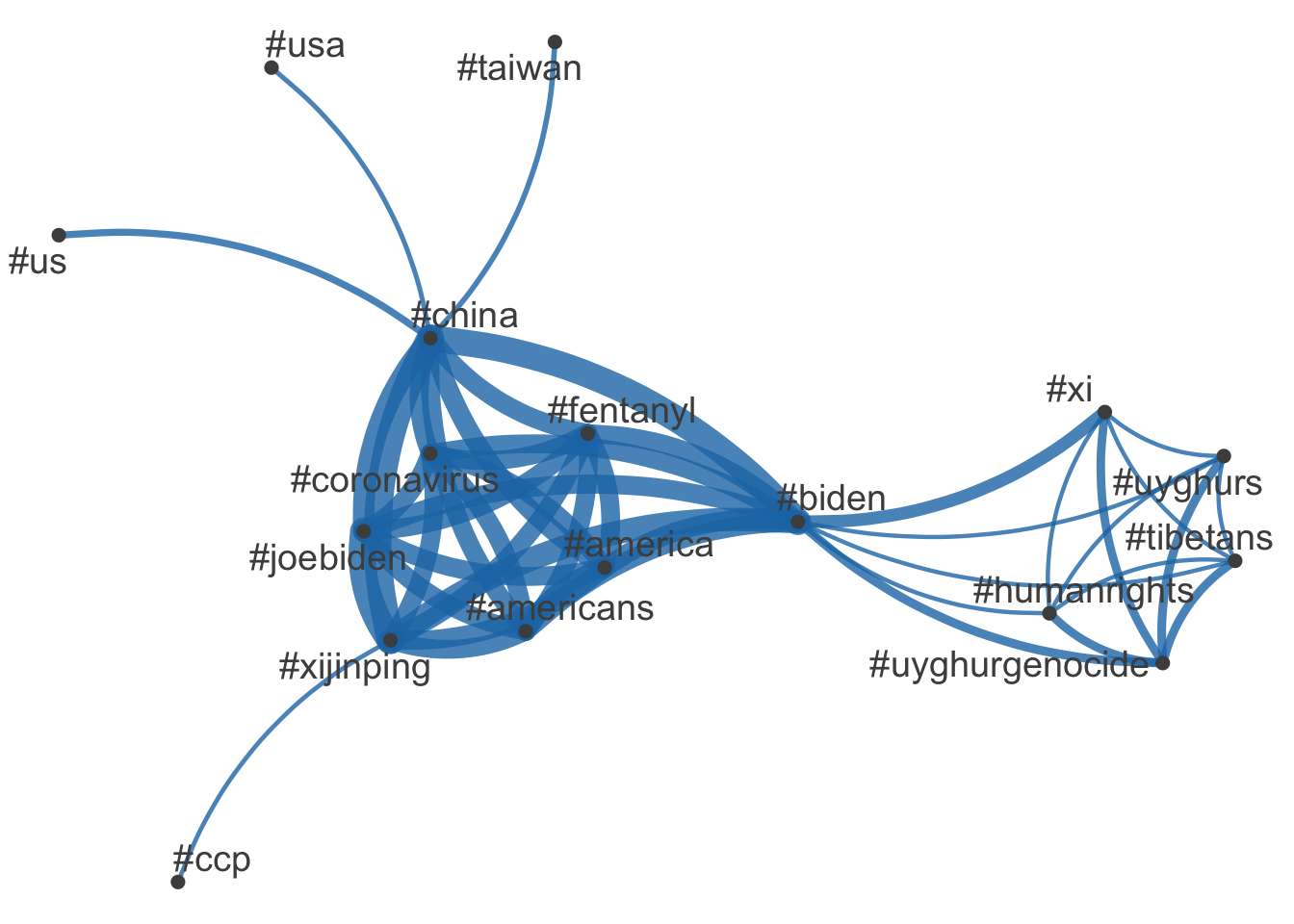
i. Any similarities and differences over time and among presidents?
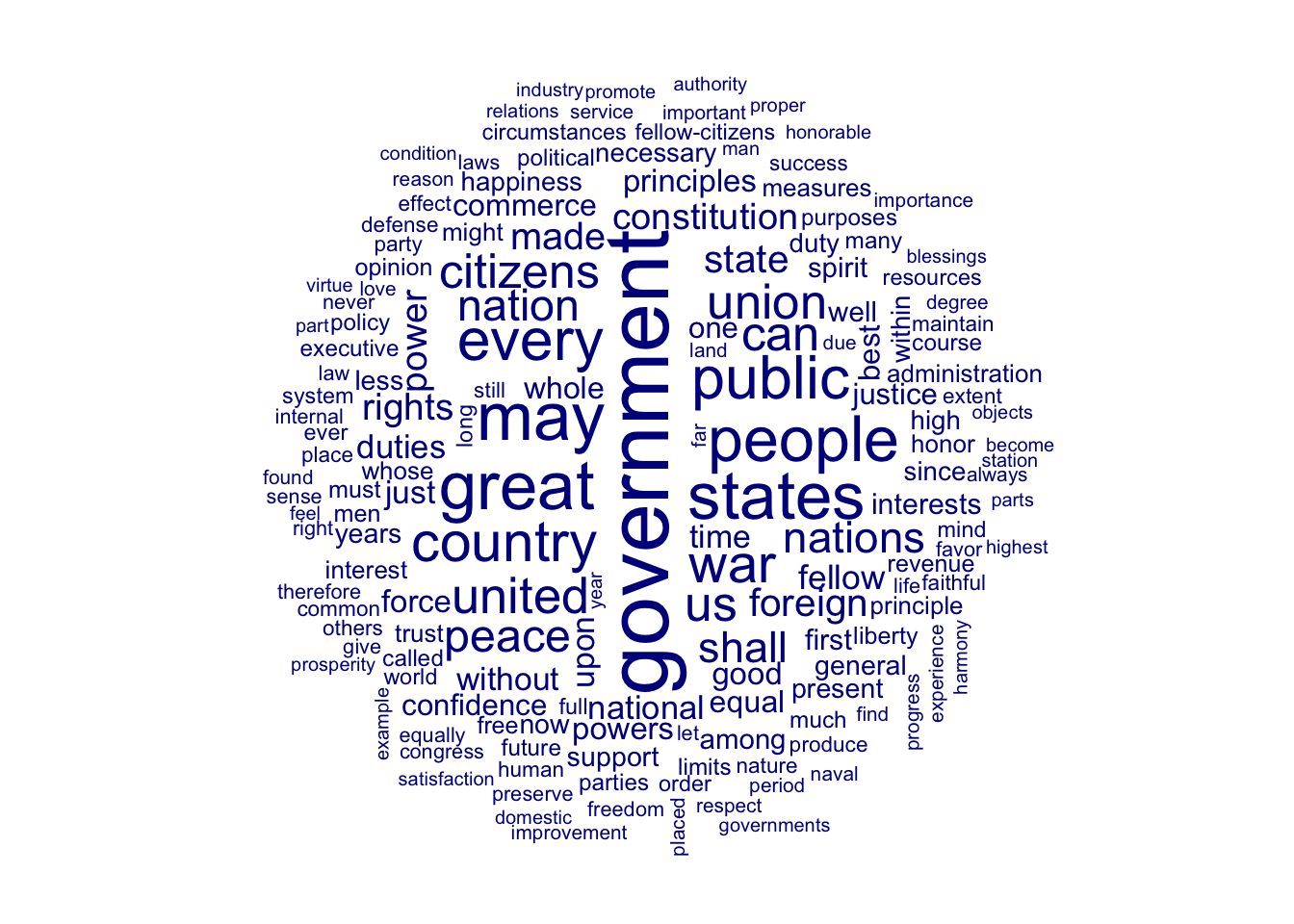
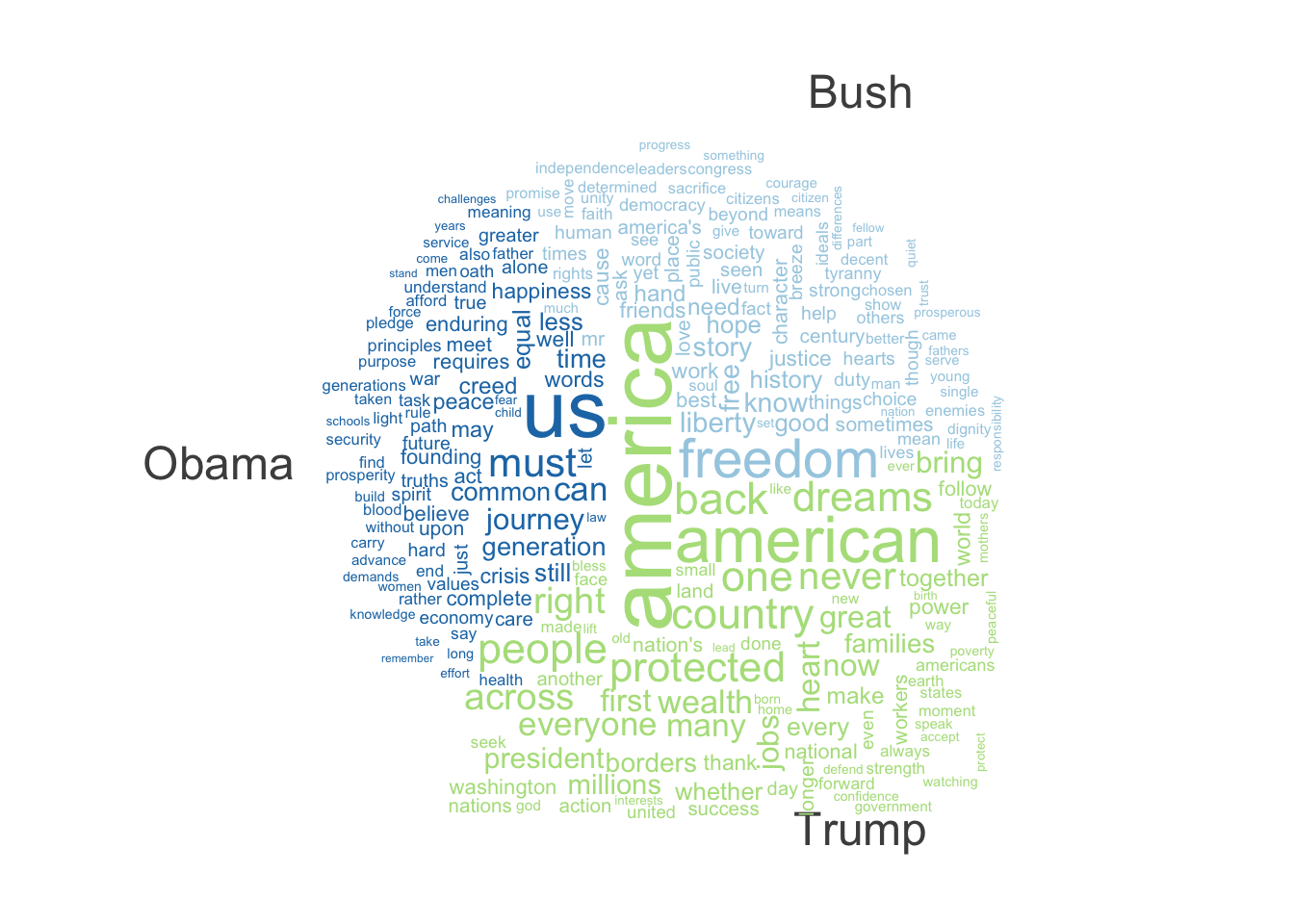
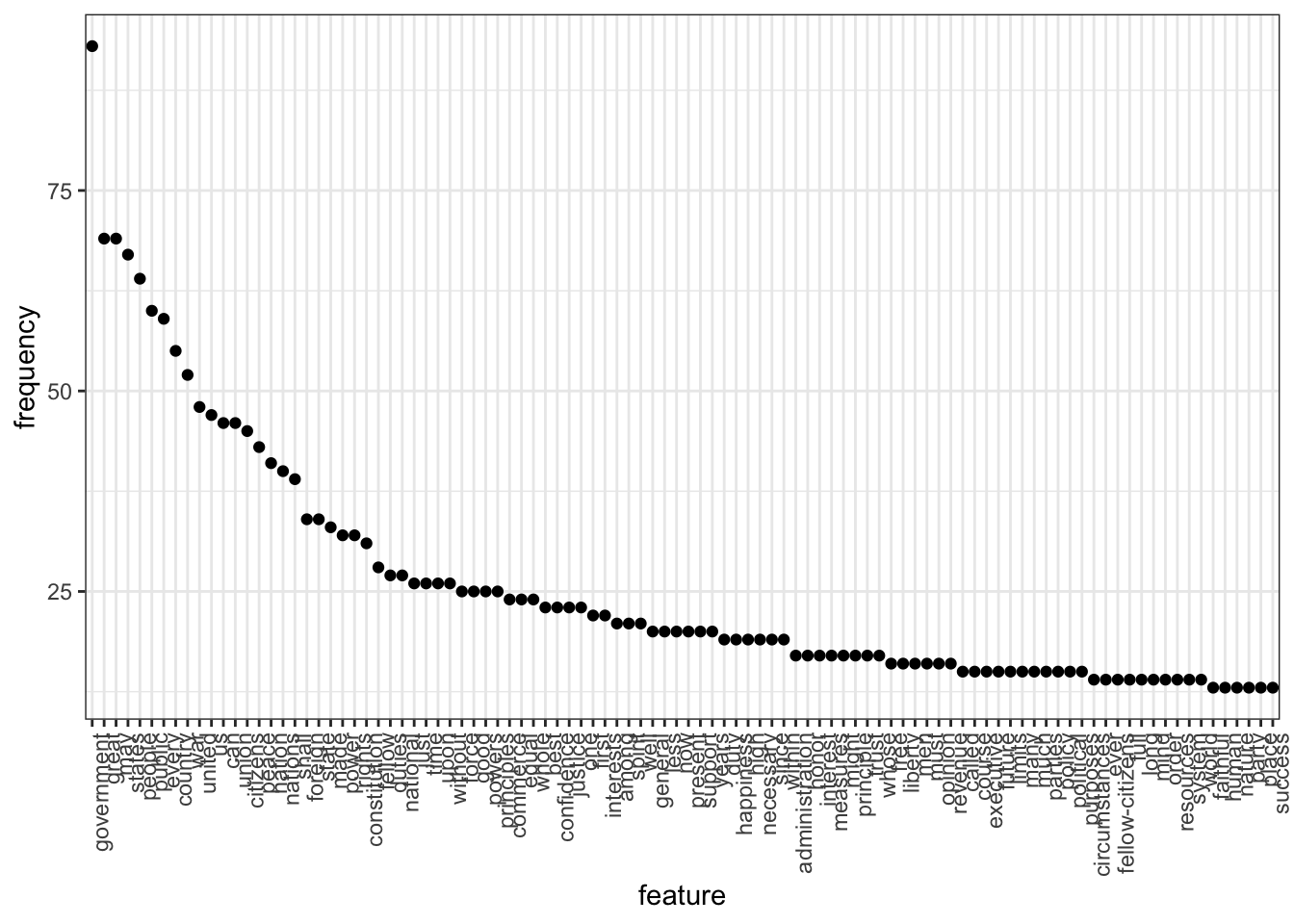
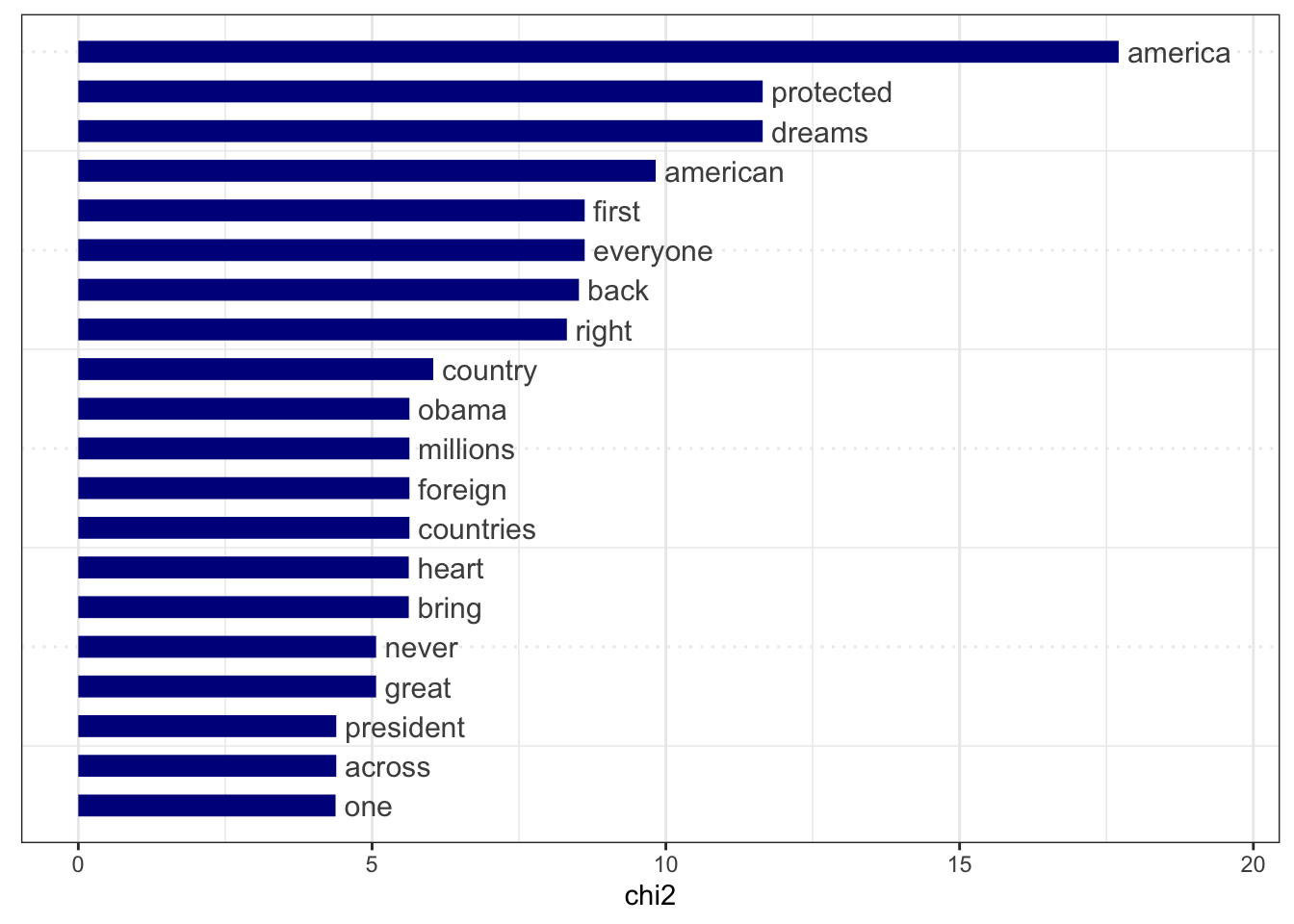
The presidents used similar words in their speeches. Many of the common words used amongst the previous and current presidents are America-centric, and relate to “America” and American values. Below are some charts showcasing these similarities and differences. The first chart is a word cloud of the most common words used by former Presidents George Bush, Barrack Obama, and Donald Trump. It can be seen that all three president used very similar wording; the largest words, i.e. the most frequently used words, were related the America or the US, or the country as a whole.
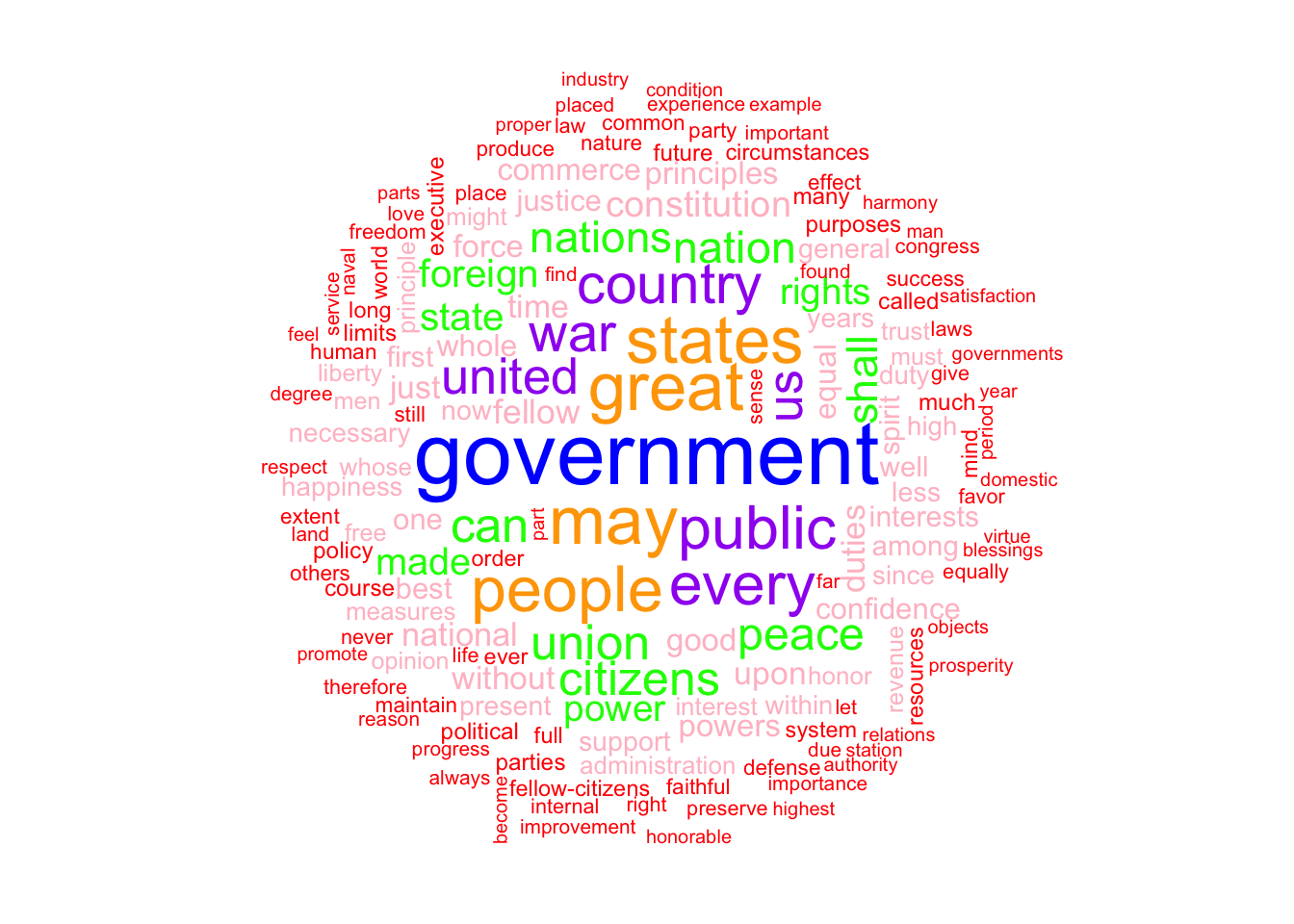
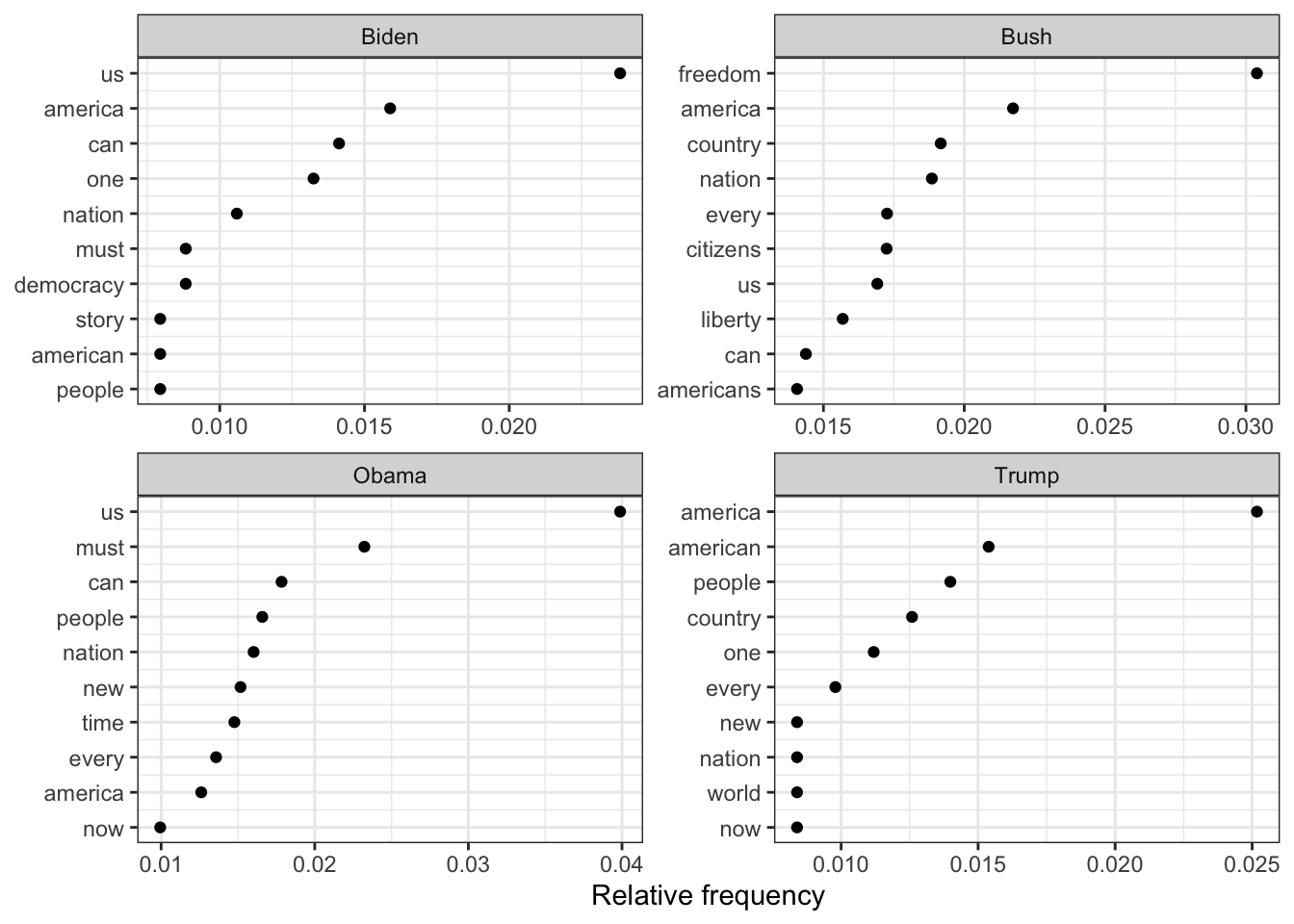
As it can be seen in the chart below, the four most recent presidents including the current president, Joe Biden, still use similar phrasing. “America”, “nation”, and “people/citizens” all topped the four presidents’ most commonly used words. The ten most common words used all still related to America and American values, such as “freedom” and “liberty”.
ii. Analyze positions of different presidents.
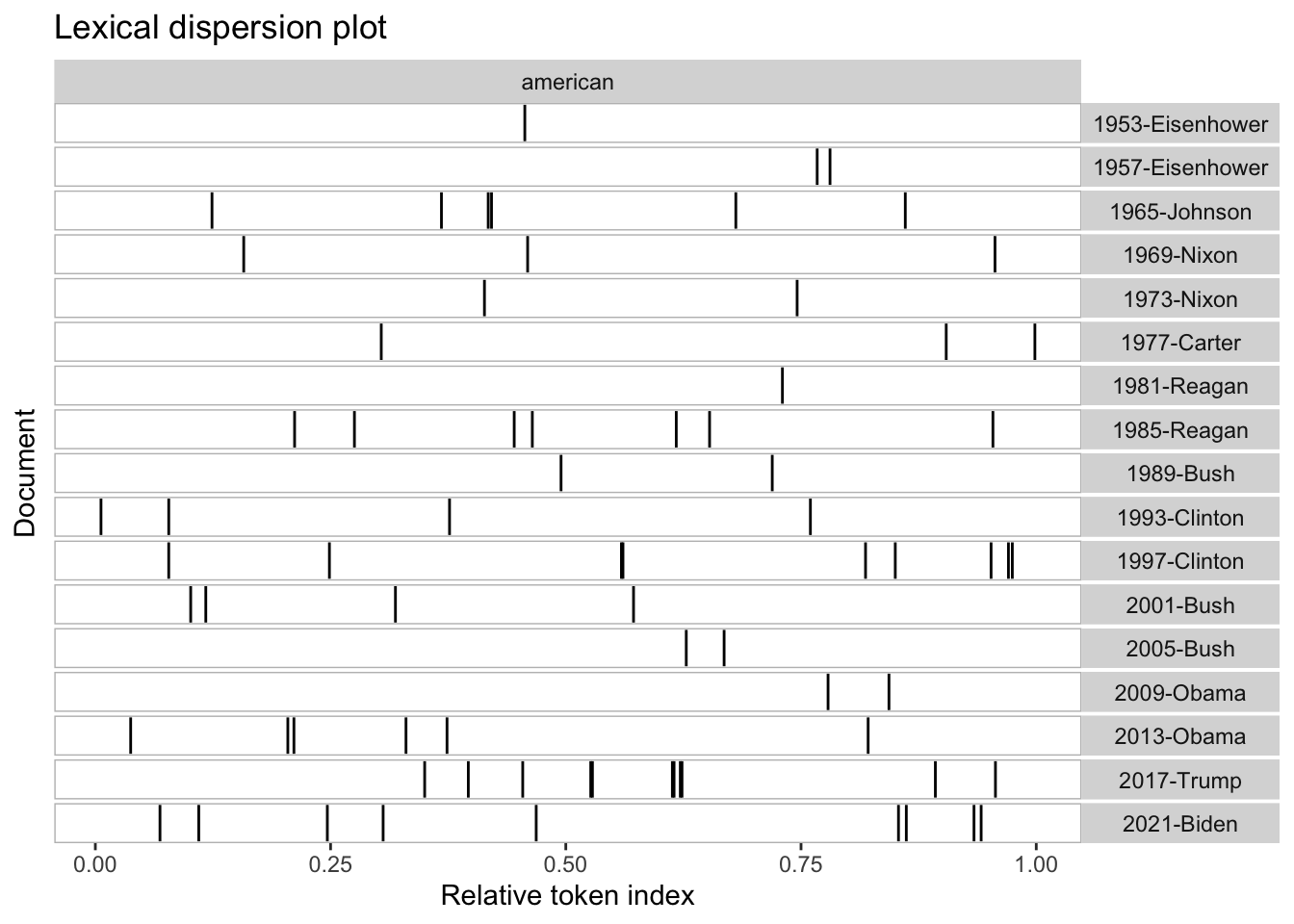
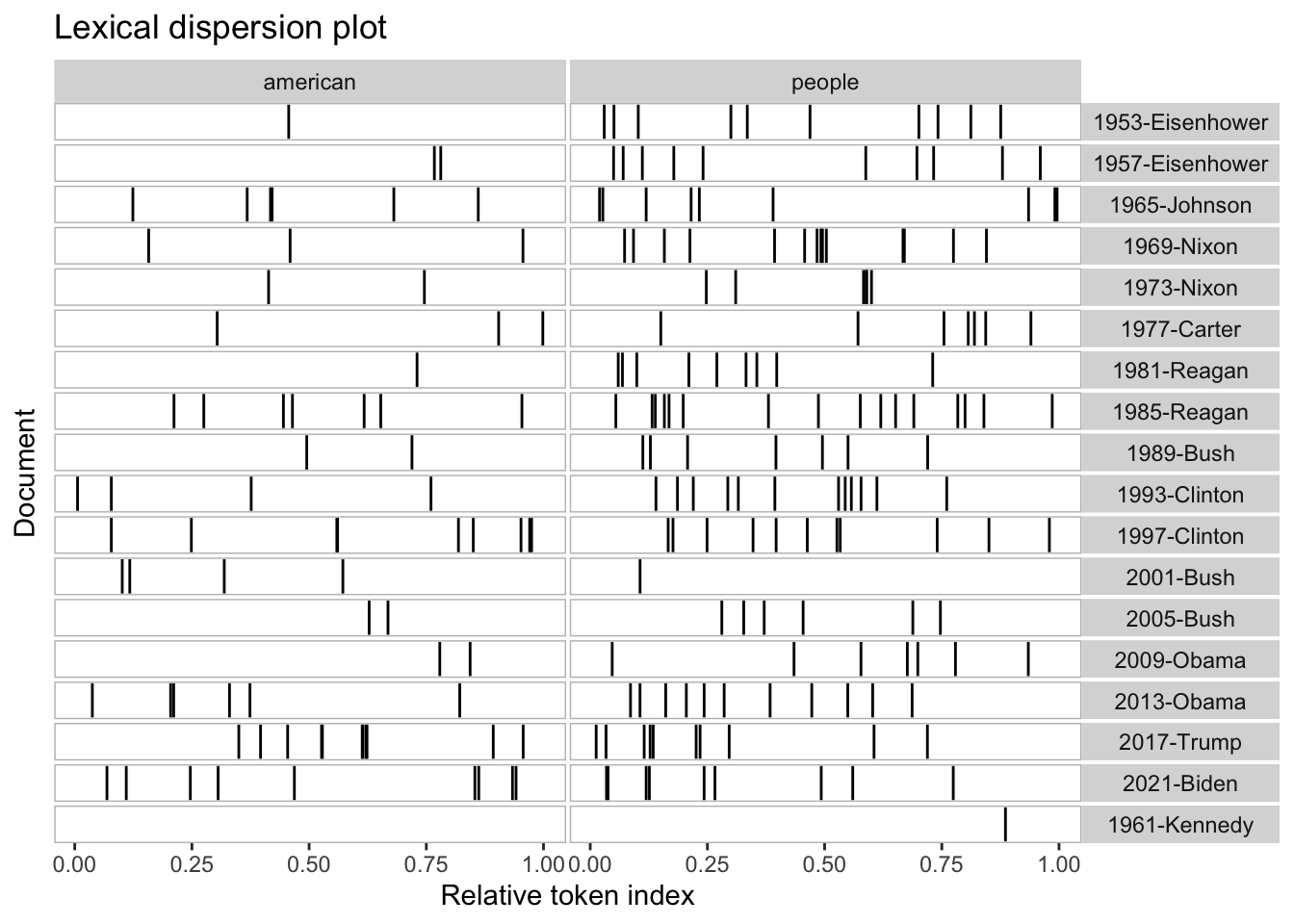
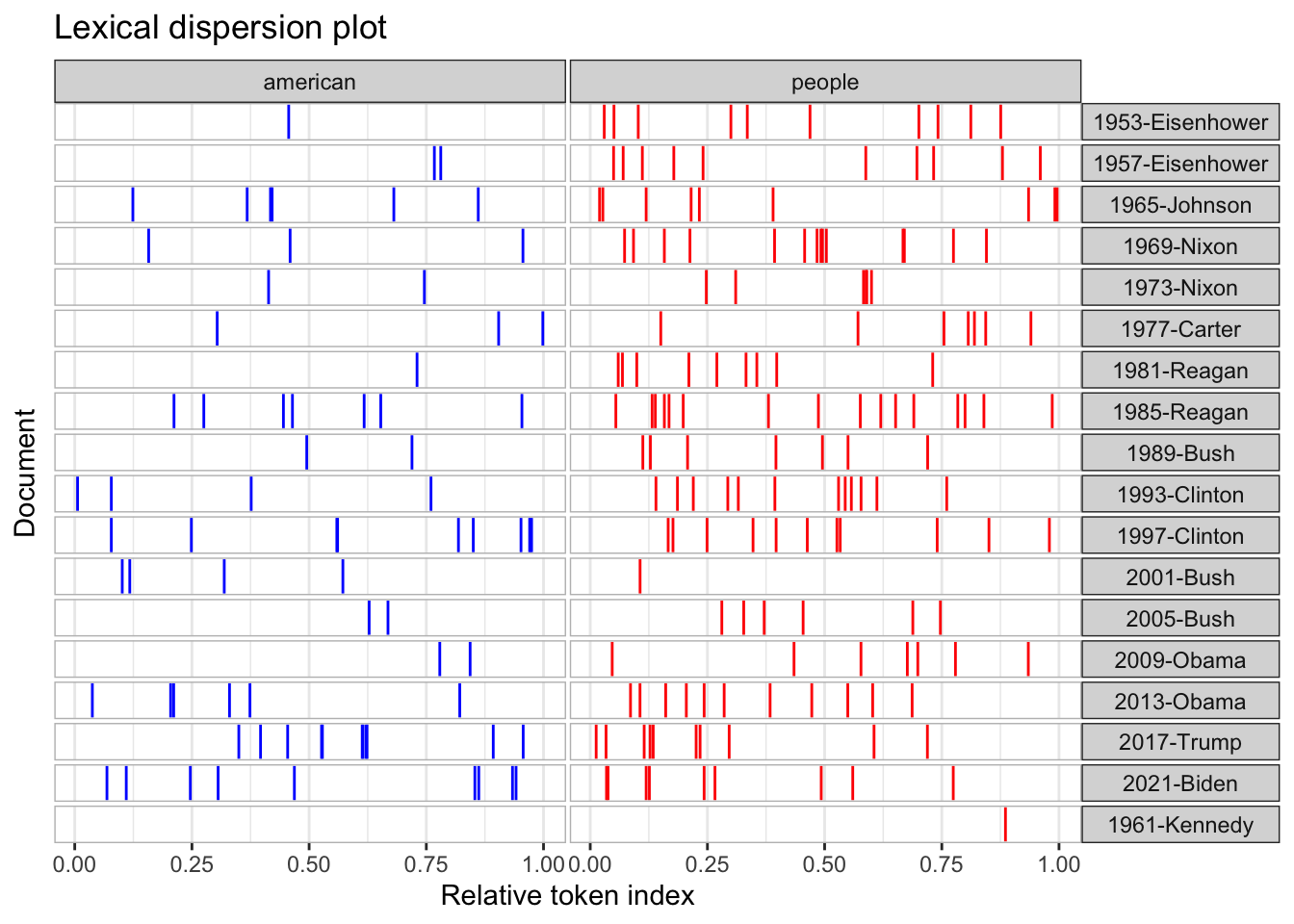
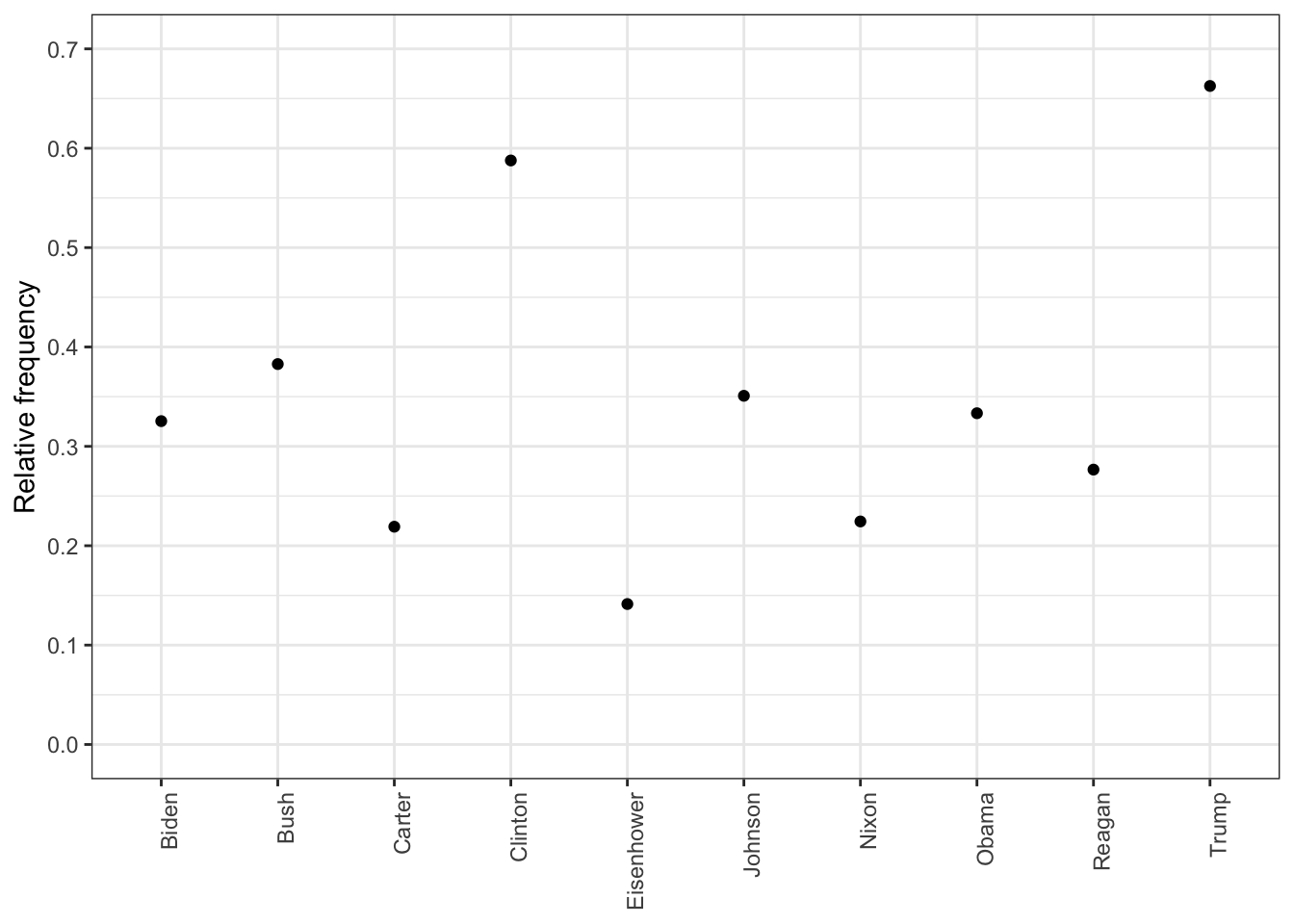
The chart below depicts the relative frequency of the word “American” used by the ten most recent presidents of the United States. As it can be seen, the frequency of this word usage is very sporadic. The one most notable feature of the chart however, is how much more frequent Donald Trump used the word “American” in comparison to the other presidents.
“Wordfish is a Poisson scaling model of one-dimensional document positions (Slapin and Proksch 2008). Wordfish also allows for scaling documents, but compared to Wordscores reference scores/texts are not required. Wordfish is an unsupervised one-dimensional text scaling method, meaning that it estimates the positions of documents solely based on the observed word frequencies.” (Quanteda)
Here is another description of what Wordfish is from Slapin and Proksch (2008), the developers of Wordfish:
“Recent advances in computational content analysis have provided scholars promising new ways for estimating party positions. However, existing text-based methods face challenges in producing valid and reliable time-series data. This article proposes a scaling algorithm called WORDFISH to estimate policy positions based on word frequencies in texts. The technique allows researchers to locate parties in one or multiple elections.” (Slapin and Proksch 2008)
# Sample program for using quanteda for text modeling and analysis# Use vignette("auth", package = "rtweet") for authentication# Documentation: vignette("quickstart", package = "quanteda")# Website: https://quanteda.io/library(quanteda)
Warning in .recacheSubclasses(def@className, def, env): undefined subclass
"packedMatrix" of class "mMatrix"; definition not updated
Warning in .recacheSubclasses(def@className, def, env): undefined subclass
"packedMatrix" of class "replValueSp"; definition not updated
See https://quanteda.io for tutorials and examples.
library(quanteda.textmodels)library(quanteda.textplots)library(readr)library(ggplot2)# Twitter data about President Biden and Xi summit in November 2021# Do some background search/study on the eventsummit <-read_csv("https://raw.githubusercontent.com/datageneration/datamethods/master/textanalytics/summit_11162021.csv")
Rows: 14520 Columns: 90
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (50): screen_name, text, source, reply_to_screen_name, hashtags, symbol...
dbl (26): user_id, status_id, display_text_width, reply_to_status_id, reply...
lgl (10): is_quote, is_retweet, quote_count, reply_count, ext_media_type, q...
dttm (4): created_at, quoted_created_at, retweet_created_at, account_create...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# Wordcloud# based on US presidential inaugural address texts, and metadata (for the corpus), from 1789 to present.dfm_inaug <-corpus_subset(data_corpus_inaugural, Year <=1826) %>%dfm(remove =stopwords('english'), remove_punct =TRUE) %>%dfm_trim(min_termfreq =10, verbose =FALSE)
Warning: 'dfm.corpus()' is deprecated. Use 'tokens()' first.
Warning: '...' should not be used for tokens() arguments; use 'tokens()' first.
Warning: 'remove' is deprecated; use dfm_remove() instead
Warning: 'kwic.corpus()' is deprecated. Use 'tokens()' first.
Warning: 'kwic.corpus()' is deprecated. Use 'tokens()' first.
Warning: 'kwic.corpus()' is deprecated. Use 'tokens()' first.
g +aes(color = keyword) +scale_color_manual(values =c("blue", "red", "green")) +theme(legend.position ="none")
library("quanteda.textstats")
Warning in .recacheSubclasses(def@className, def, env): undefined subclass
"packedMatrix" of class "mMatrix"; definition not updated
Warning in .recacheSubclasses(def@className, def, env): undefined subclass
"packedMatrix" of class "replValueSp"; definition not updated
features_dfm_inaug <-textstat_frequency(dfm_inaug, n =100)# Sort by reverse frequency orderfeatures_dfm_inaug$feature <-with(features_dfm_inaug, reorder(feature, -frequency))ggplot(features_dfm_inaug, aes(x = feature, y = frequency)) +geom_point() +theme(axis.text.x =element_text(angle =90, hjust =1))
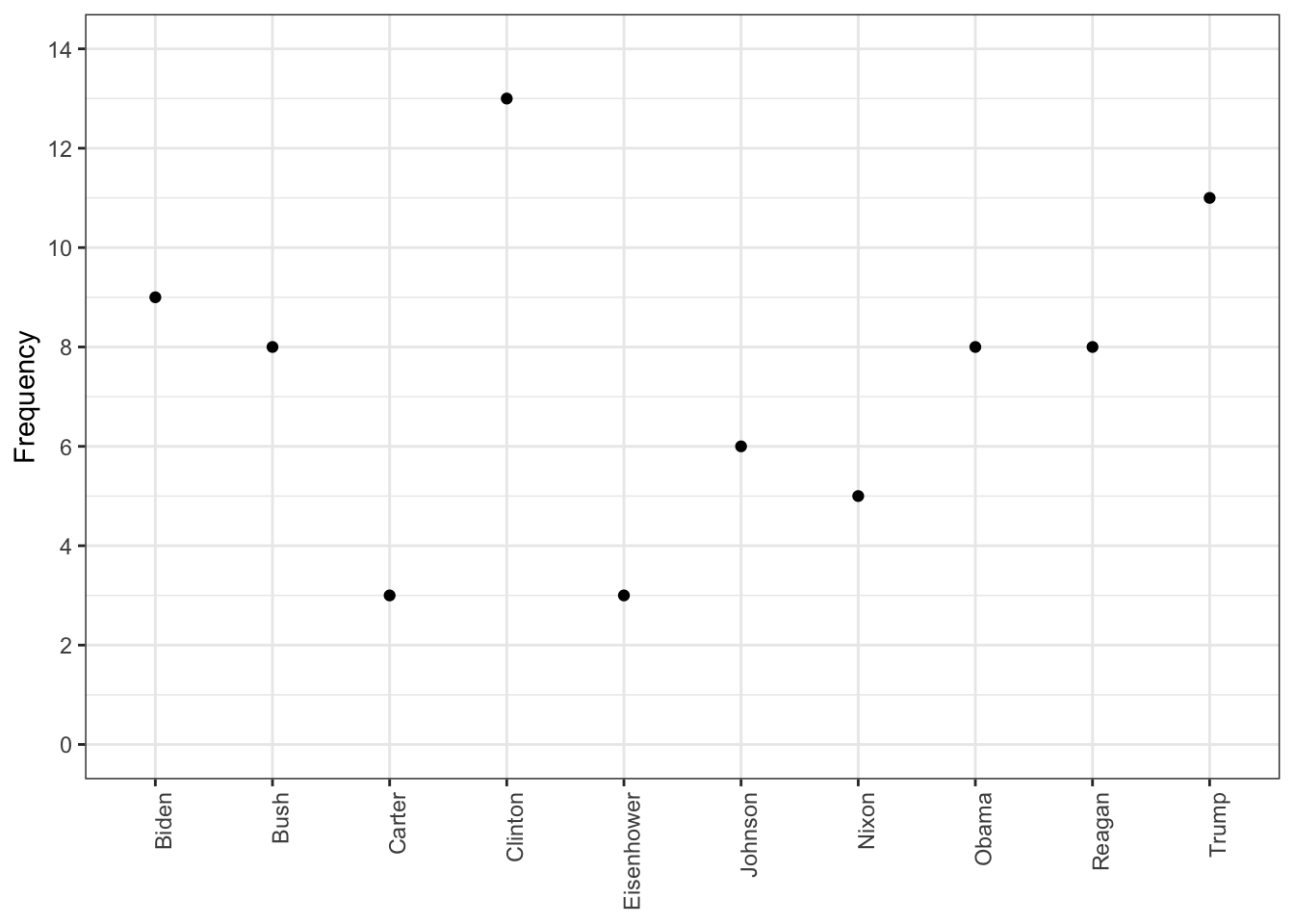
# Get frequency grouped by presidentfreq_grouped <-textstat_frequency(dfm(tokens(data_corpus_inaugural_subset)), groups = data_corpus_inaugural_subset$President)# Filter the term "american"freq_american <-subset(freq_grouped, freq_grouped$feature %in%"american") ggplot(freq_american, aes(x = group, y = frequency)) +geom_point() +scale_y_continuous(limits =c(0, 14), breaks =c(seq(0, 14, 2))) +xlab(NULL) +ylab("Frequency") +theme(axis.text.x =element_text(angle =90, hjust =1))
Document-feature matrix of: 6 documents, 4,346 features (85.57% sparse) and 4 docvars.
features
docs my friends , before i
1953-Eisenhower 0.14582574 0.14582574 4.593511 0.1822822 0.10936930
1957-Eisenhower 0.20975354 0.10487677 6.345045 0.1573152 0.05243838
1961-Kennedy 0.19467878 0.06489293 5.451006 0.1297859 0.32446463
1965-Johnson 0.17543860 0.05847953 5.555556 0.2339181 0.87719298
1969-Nixon 0.28973510 0 5.546358 0.1241722 0.86920530
1973-Nixon 0.05012531 0.05012531 4.812030 0.2005013 0.60150376
features
docs begin the expression of those
1953-Eisenhower 0.03645643 6.234050 0.03645643 5.176814 0.1458257
1957-Eisenhower 0 5.977976 0 5.034085 0.1573152
1961-Kennedy 0.19467878 5.580792 0 4.218040 0.4542505
1965-Johnson 0 4.502924 0 3.333333 0.1754386
1969-Nixon 0 5.629139 0 3.890728 0.4552980
1973-Nixon 0 4.160401 0 3.408521 0.3007519
[ reached max_nfeat ... 4,336 more features ]
rel_freq <-textstat_frequency(dfm_rel_freq, groups = dfm_rel_freq$President)# Filter the term "american"rel_freq_american <-subset(rel_freq, feature %in%"american") ggplot(rel_freq_american, aes(x = group, y = frequency)) +geom_point() +scale_y_continuous(limits =c(0, 0.7), breaks =c(seq(0, 0.7, 0.1))) +xlab(NULL) +ylab("Relative frequency") +theme(axis.text.x =element_text(angle =90, hjust =1))
dfm_weight_pres <- data_corpus_inaugural %>%corpus_subset(Year >2000) %>%tokens(remove_punct =TRUE) %>%tokens_remove(stopwords("english")) %>%dfm() %>%dfm_weight(scheme ="prop")# Calculate relative frequency by presidentfreq_weight <-textstat_frequency(dfm_weight_pres, n =10, groups = dfm_weight_pres$President)ggplot(data = freq_weight, aes(x =nrow(freq_weight):1, y = frequency)) +geom_point() +facet_wrap(~ group, scales ="free") +coord_flip() +scale_x_continuous(breaks =nrow(freq_weight):1,labels = freq_weight$feature) +labs(x =NULL, y ="Relative frequency")
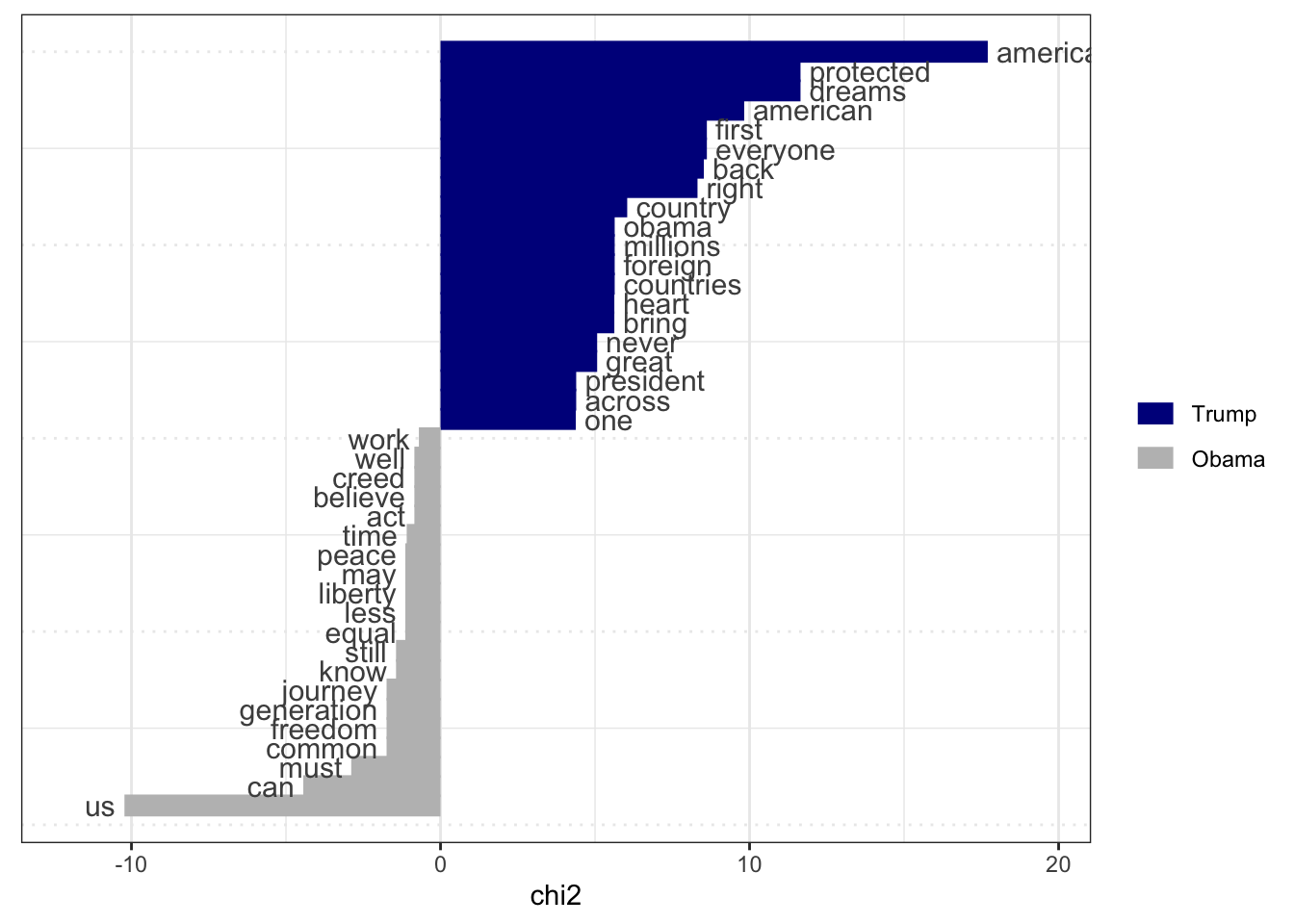
# Only select speeches by Obama and Trumppres_corpus <-corpus_subset(data_corpus_inaugural, President %in%c("Obama", "Trump"))# Create a dfm grouped by presidentpres_dfm <-tokens(pres_corpus, remove_punct =TRUE) %>%tokens_remove(stopwords("english")) %>%tokens_group(groups = President) %>%dfm()# Calculate keyness and determine Trump as target groupresult_keyness <-textstat_keyness(pres_dfm, target ="Trump")# Plot estimated word keynesstextplot_keyness(result_keyness)
# Plot without the reference text (in this case Obama)textplot_keyness(result_keyness, show_reference =FALSE)
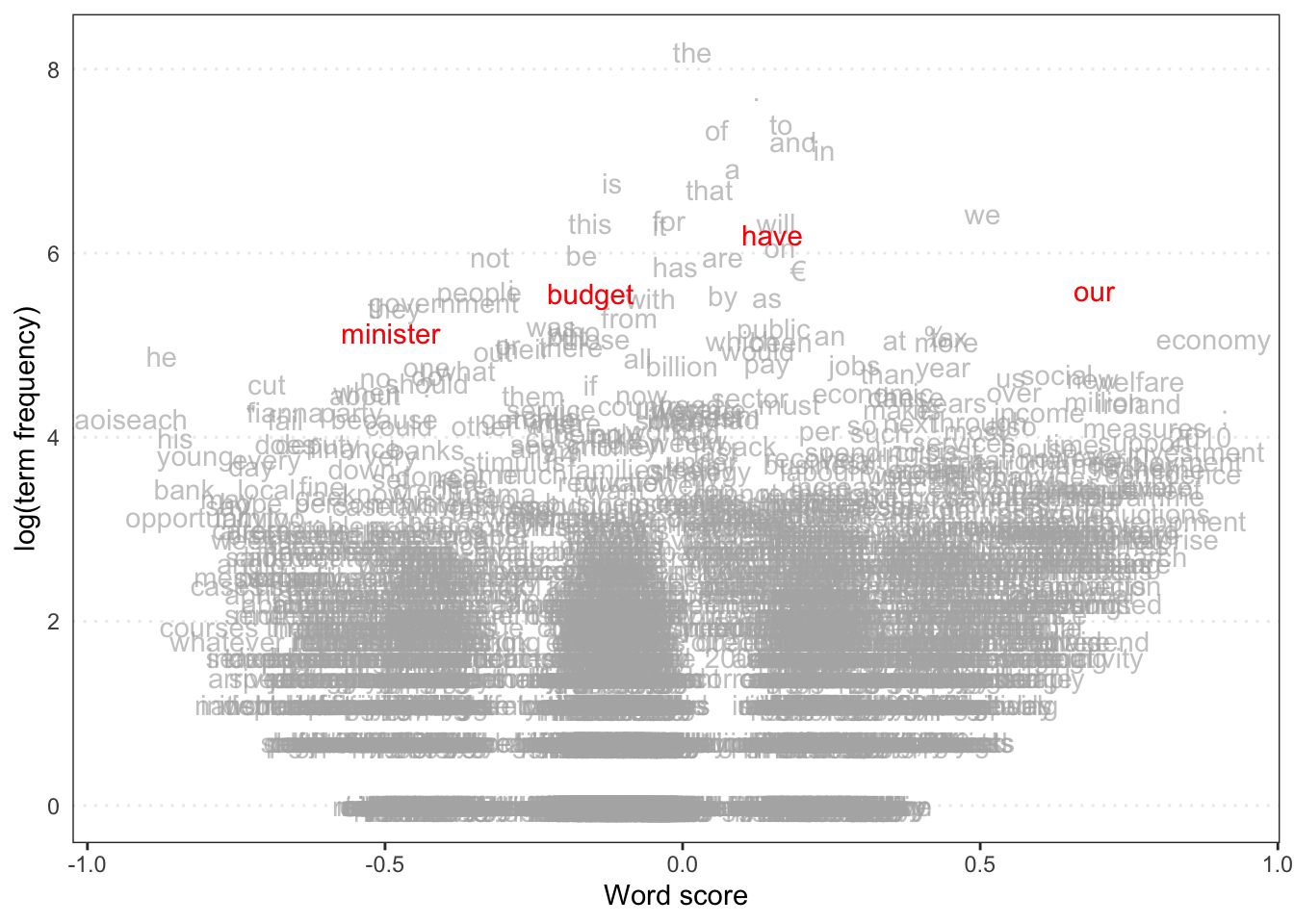
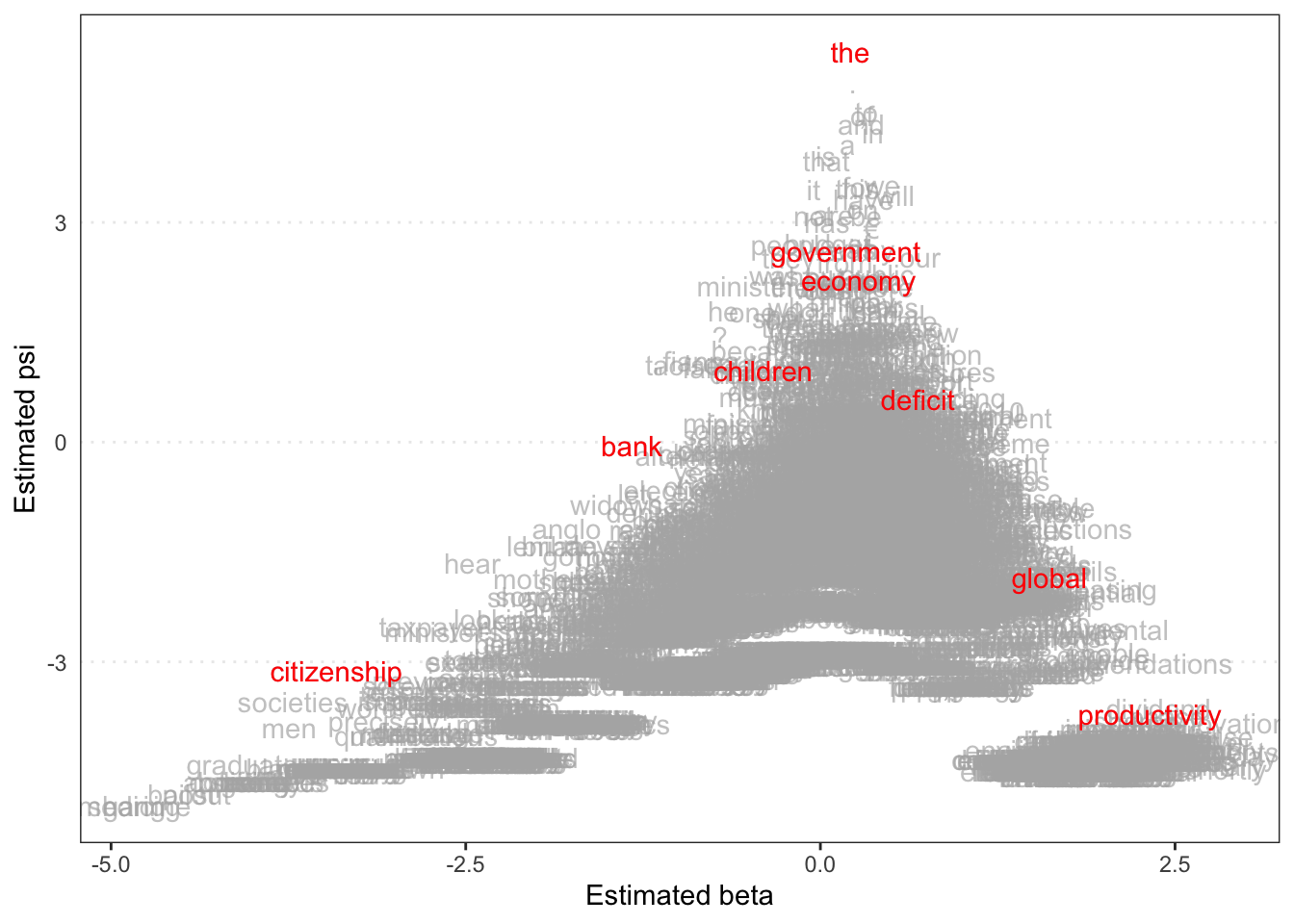
library("quanteda.textmodels")# Transform corpus to dfmdata(data_corpus_irishbudget2010, package ="quanteda.textmodels")ie_dfm <-dfm(tokens(data_corpus_irishbudget2010))# Set reference scoresrefscores <-c(rep(NA, 4), 1, -1, rep(NA, 8))# Predict Wordscores modelws <-textmodel_wordscores(ie_dfm, y = refscores, smooth =1)# Plot estimated word positions (highlight words and print them in red)textplot_scale1d(ws,highlighted =c("minister", "have", "our", "budget"), highlighted_color ="red")
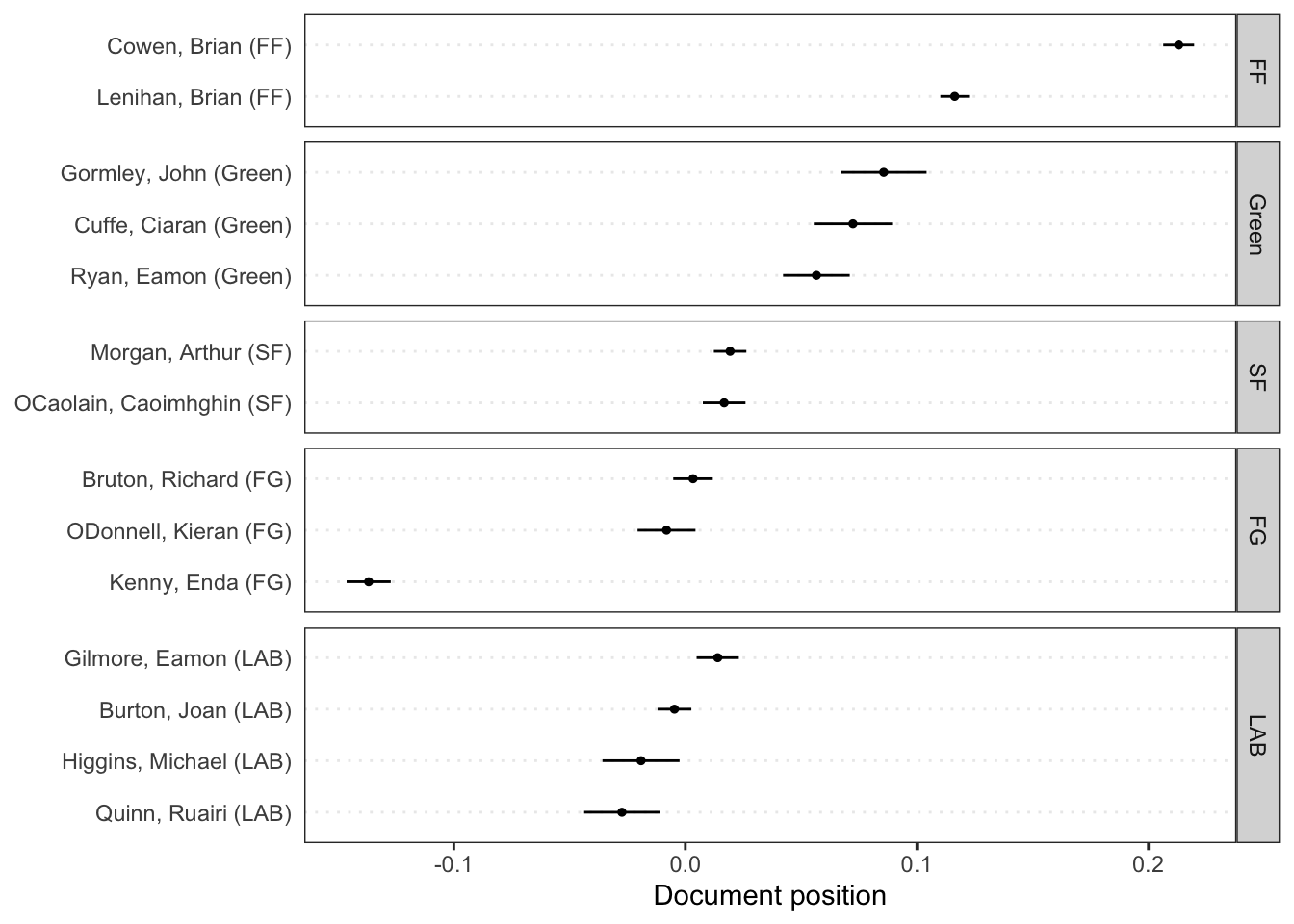
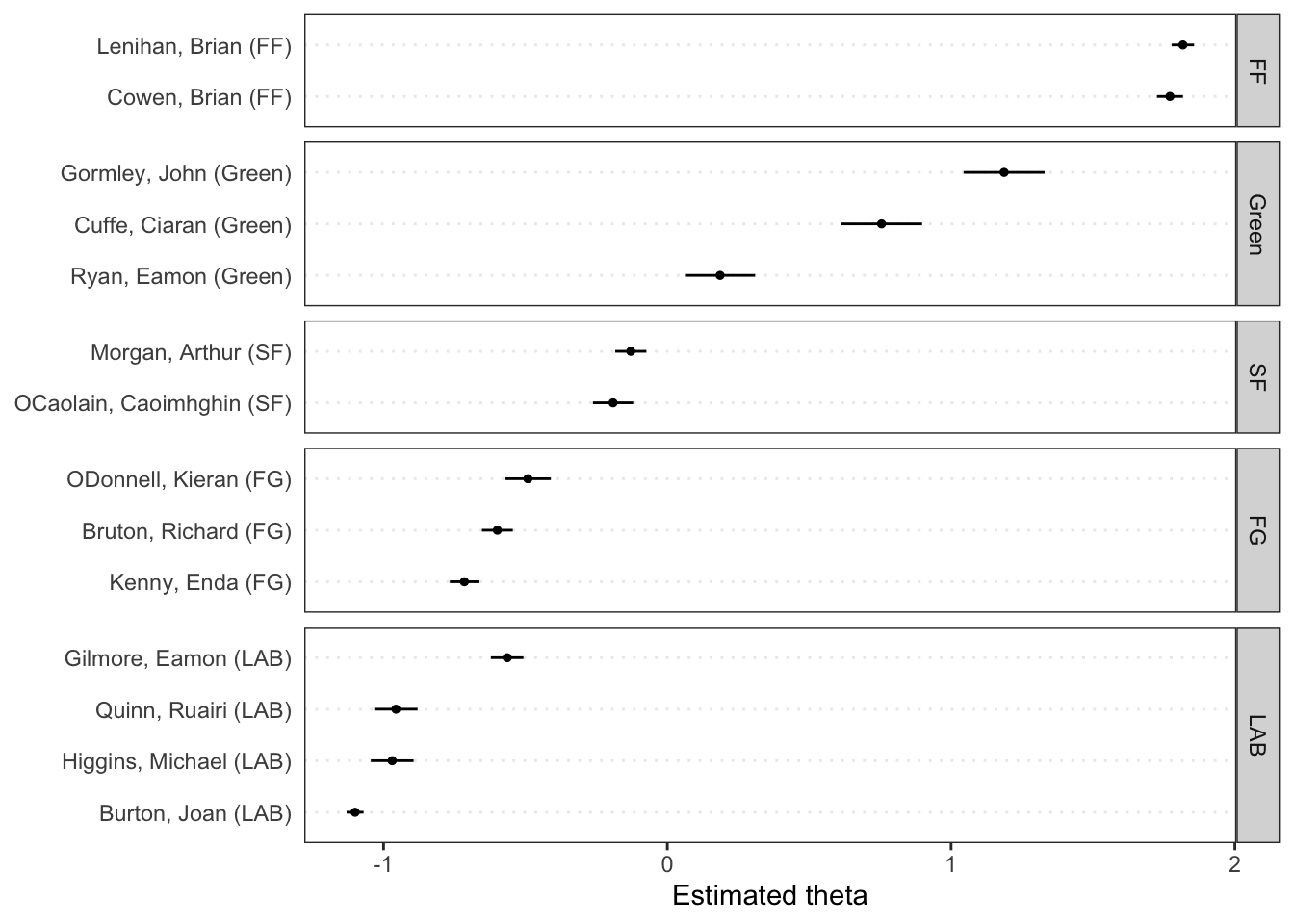
# Get predictionspred <-predict(ws, se.fit =TRUE)# Plot estimated document positions and group by "party" variabletextplot_scale1d(pred, margin ="documents",groups =docvars(data_corpus_irishbudget2010, "party"))
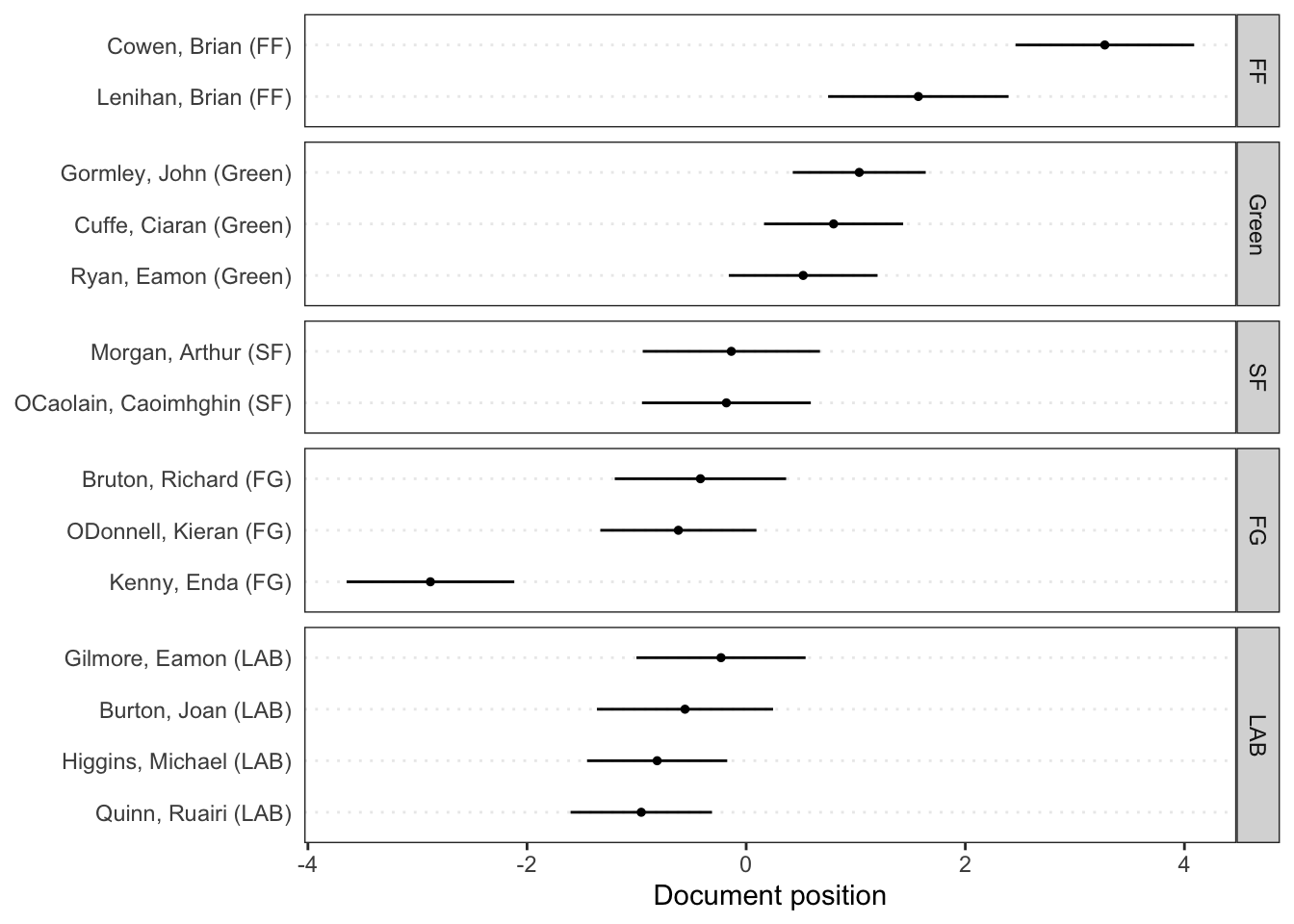
# Plot estimated document positions using the LBG transformation and group by "party" variablepred_lbg <-predict(ws, se.fit =TRUE, rescaling ="lbg")textplot_scale1d(pred_lbg, margin ="documents",groups =docvars(data_corpus_irishbudget2010, "party"))
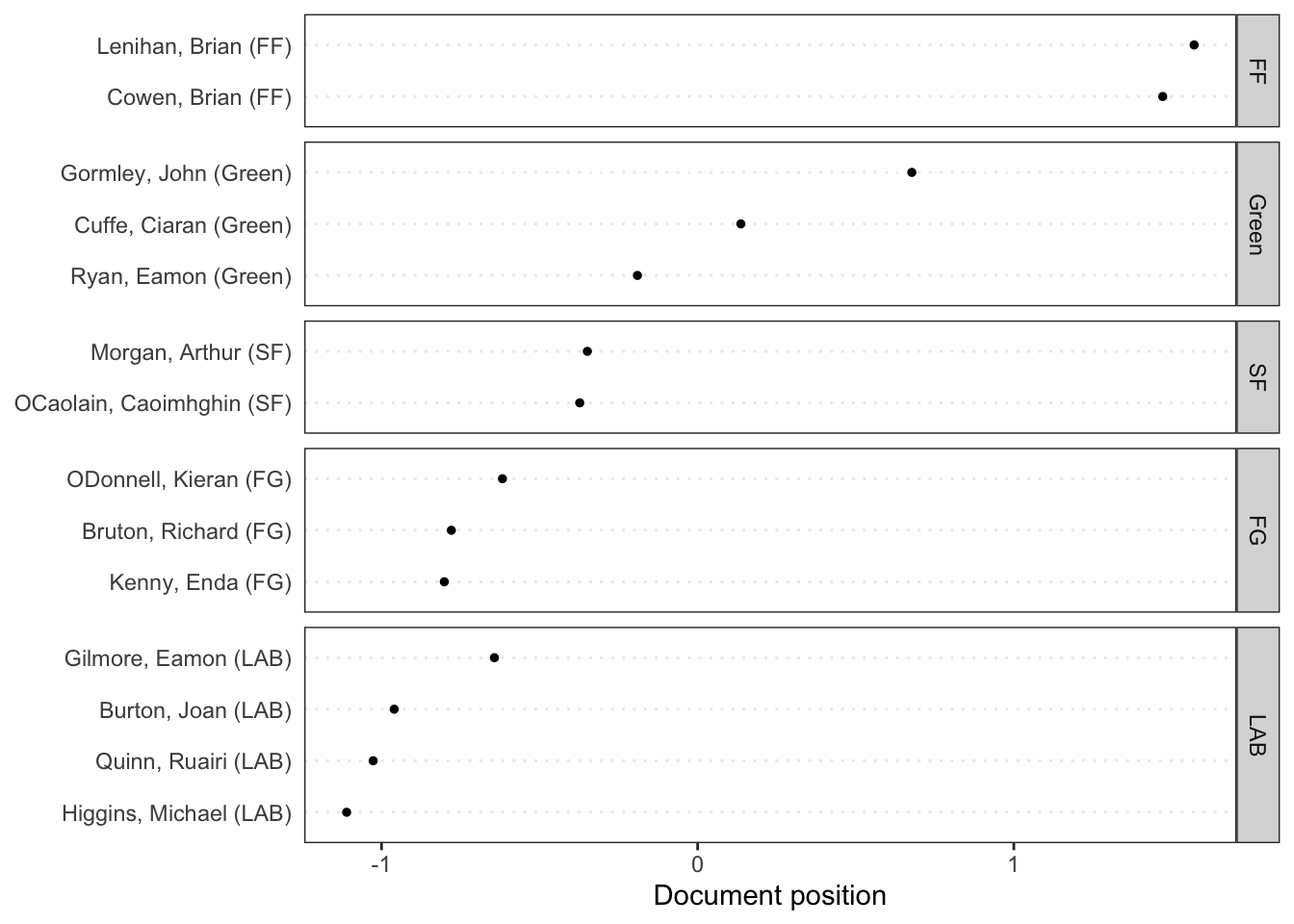
# Plot estimated document positionstextplot_scale1d(wf, groups = data_corpus_irishbudget2010$party)
# Transform corpus to dfmie_dfm <-dfm(tokens(data_corpus_irishbudget2010))# Run correspondence analysis on dfmca <-textmodel_ca(ie_dfm)# Plot estimated positions and group by partytextplot_scale1d(ca, margin ="documents",groups =docvars(data_corpus_irishbudget2010, "party"))